Machine Learning
Typical workflow
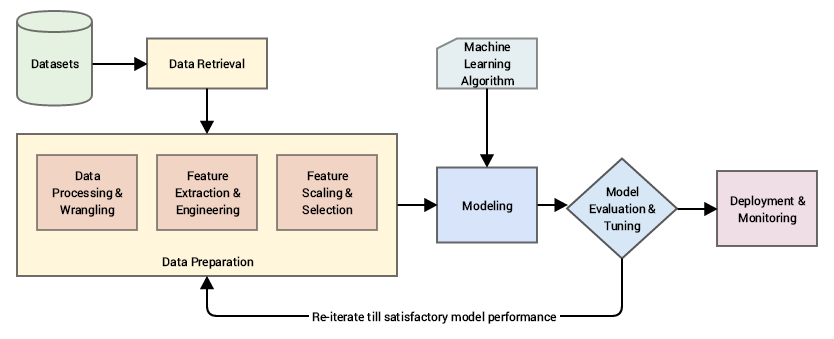
- Machine learning is a continuous cycle.
- When writing the final report, follow these instructions
Development and operations
- Exploring and processing data is tightly coupled with modeling.
- Together they are considered development.
- Comparatively deployment is more tightly coupled with the production environment.
- Deployment is typically considered operations.
- The division between development and operations softens over time.
- Advances in cloud services, like SageMaker and ML Engine, and deployment technologies, like Containers and REST API, enables analysts to handle certain aspects of deployment.
- Deployment is not commonly included in machine learning curriculum.
Use case formulation
- Identify the use case, define the business value (labor/cost savings, fraud prevention and reduction)
- Re-state business problem as machine learning task, e.g., anomaly detection or classification.
- Define “success” – choose metric, e.g., AUC, and minimum acceptable performance.
- Quick and dirty literature review.
- Define necessary system architecture.
- Assess potential sources of risk.
- Commission exploratory analysis or feasibility study, if appropriate.
Exploring and processing data
Data retrieval
- Identify relevant and necessary data and available data sources.
- Use in-house example data repositories, or use datasets that are publicly available.
- Structured and unstructured data that often includes missing or noisy data.
- For example, files, databases, big data storage, sensors or social networks.
- If using a public API, understand the limitations of the API before using them.
- The more training examples, the better.
- Make sure the number of samples for every class or topic is not overly imbalanced.
- Make sure that the samples adequately cover the space of possible inputs.
Data exploration
- EDA refers to the ad hoc querying and visualization of data to find valuable patterns.
- The purpose of EDA is to use summary statistics and visualizations to better understand data.
- Find clues about the tendencies of the data and its quality (completeness, correctness)
- Formulate assumptions and the hypothesis of your analysis.
- Rapidly explore and de-risk a use case before significant engineering resources are dedicated.
- For example, inspect descriptive statistics, visualization, detection of garbage data/noise/outlier values, signal-to-noise ratio.
- Quantify suitability of data for ML: number of records and features, availability and quality of labels.
Data cleaning and preprocessing
Data scientists spend 80% of time cleaning their data and 20% of time complaining about it.
- Data-gathering methods are often loosely controlled, resulting in corrupted values.
- The raw data retrieved in the first step is in most cases unusable by ML algorithms.
- "The heart of data science": data preparation takes 60-80% of the whole pipeline.
- The product of data preprocessing is the final training set.
- Deals with missing data imputation, typecasting, handling duplicates and outliers, etc.
- Thus domain knowledge is very important.
- Various programming languages, frameworks and tools are available.
- Tools such as R, Python, Spark, KNIME or RapidMiner can be used together.
- Data preparation cannot be fully automated; at least not in the beginning.
- Avoiding numerous components speeds up a data science project.
- Leverage a streaming ingestion or/and preprocessing framework.
- Data ETL and vectorization pipeline should be configurable, fully tested, scalable, automatable.
- Data Preprocessing in Machine Learning Projects
- Data cleansing:
- Clean the data to find any anomalous values caused by errors in data entry or measurement.
- May be performed interactively with data wrangling tools, or as batch processing through scripting.
- Data wrangling:
- Data wrangling is a simple, intuitive way of data preparation with a graphical tool.
- The focus of these tools is on ease-of-use and agile data preparation (by everyone)
- Not as powerful as data preprocessing frameworks and often used for the last mile.
- Tool examples: OpenRefine, Trifacta, TIBCO Spotfire
- Data transformation:
- The process of converting data from one format or structure into another format or structure.
- Involves normalization, transformation and aggregation of data using ETL methods.
- Data integration:
- Combining data residing in different sources and providing users with a unified view.
- Data reduction:
- Using various strategies, reducing the size of data but yielding the same outcome.
Feature extraction and engineering
"Applied machine learning" is basically feature engineering.
- Preprocessed and wrangled data reaches the state where it can be utilized by the feature engineering.
- Features are important to predictive models and influence results.
- The feature engineering process is both difficult and expensive but can be semi-automated.
- Use domain knowledge of the data to select or create features.
- Discard features likely to expose you to the risk of over-fitting your model.
- Feature Engineering: What Powers Machine Learning
Modeling
Modeling
- The modeling can’t occur without having the data being prepared for the modeling process.
- Selecting a model is totally depended on data type which is been extracted.
- A model is basically a generalized representation of data.
- Develop a model using established ML techniques or by defining new operations and approaches.
- Thorough literature review with short list of proposed machine-learning approaches.
- Given candidate models of similar predictive or explanatory power, the simplest model wins.
Model evaluation and tuning
- Specify experimental (i.e. training/test split) protocol.
- Train and evaluate ML models to assess presence (or absence) of predictive signal.
- Evaluate the model to determine whether the accuracy of the inferences is acceptable.
- Tune and debug model training.
- ML algorithms have different parameters or knobs, which can be tuned.
- Model tuning works by iterating over different settings of hyperparameters.
- Document experiments and model performance to date.
- Save deployable artifacts (transforms, models, etc.)
- Developing a model is a process of experimentation and incremental adjustment.
- Expect to spend a lot of time refining and modifying your model to get the best results.
- Establish a threshold of success before begin to know when to stop refining the model.
Deployment
Model deployment and monitoring
- Re-engineer a model before integrating it with the application:
- Create a fully tuned model and a reusable software artifact.
- Create a reliable, reusable software pipeline for re-training models in the future.
- Deploy trained model (and transform, if needed) as service, integrate with other software/processes.
- Set up and manage A/B tests to compare, e.g., new vs. old models.
- Monitor and log deployed model status, performance, and accuracy.
- Gather statistics on deployed models to feed back into training and deployment.