Regularization
- This is a form of regression that penalizes the weights of the nodes and shrinks them towards zero.
- Discourages learning a more complex or flexible model, so as to avoid the risk of overfitting.
- Forces the downstream hidden units not to rely too much on the previous units by introducing noise.
Overfitting
- The concept of regularization plays an important role in preventing overfitting.
- The primary reason overfitting happens is because the model learns even the tiniest details (noise) present in the data.
- It's always better to use regularization methods to control overfitting instead of the number of neurons.
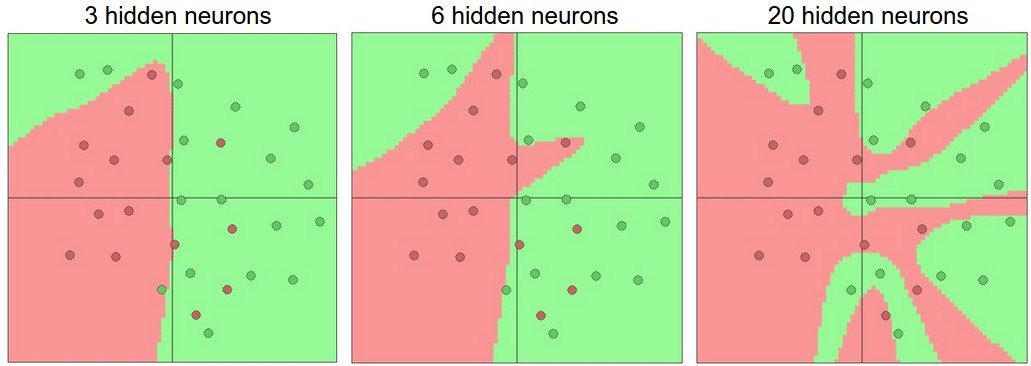
- Overfit -> Reduce Overfitting -> There is no step 3. Remember overfitting doesn’t mean having a lower training loss than validation loss, that is normal. It means you have seen your validation error getting worse, until you see that happening you’re not overfitting.
Examples of regularization
- K-means: limiting the splits to avoid redundant classes
- Random forests: limiting the tree depth, limiting new features (number of branches)
- Neural networks: limiting the model complexity (number of weights)
L1 and L2 regularization
- If model complexity is a function of weights, a feature weight with a high absolute value is more complex.
- Due to the addition of a regularization term to the loss function, the values of weight matrices decrease because it assumes that a neural network with smaller weight matrices leads to simpler models.
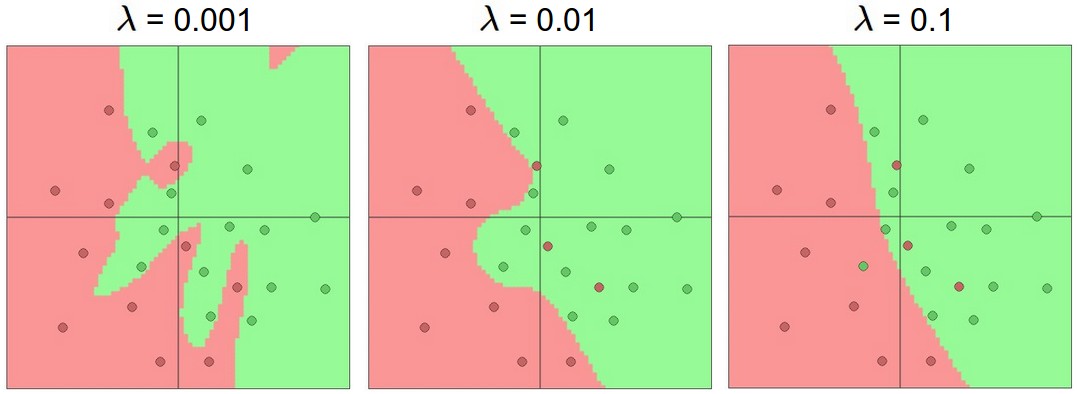
- The (non-negative) parameter \(\lambda\) controls the amount of regularization applied to the model.
- The larger \(\lambda\) is, the more the coefficients are shrunk toward zero.
Comparison
- L1 or Lasso penalty is the sum of the weights:
$$L1=\large{\lambda\sum{||W||_1}}$$
- L2 or Ridge penalty is the sum of the square of the weights:
$$L2=\large{\lambda\sum{||W||_2^2}}$$
- L1-norm produces sparse coefficients.
- L1 norm is more robust to the outliers:
- There is no square term to blow up the error difference of the outliers and the minimization algorithm keeps its focus on the data instead of the outliers.
- The fact that L1 can be used for noisy data is very appealing and is exploited a lot.
- The general frustration with the L1 norm is usually directed toward the fact that it is not differentiable and is not attractive to use in an optimization setting.
- L2 scores are usually overall better than L1.
- For more details, see Linear Models.
Weight decay
- L2 regularization and weight decay are not identical
- L2 regularization is not effective in Adam.
- Weight decay is equally effective in both SGD and Adam.
- Optimal weight decay depends on the total number of batch passes/weight updates.
- AdamW and Super-convergence is now the fastest way to train neural nets
Dropout
- The most frequently used regularization technique in the field of deep learning.
- The key idea is to randomly drop units (along with their connections) from the neural network during training. This prevents units from co-adapting too much. Also divide each dropout layer by probability to keep the same expected value for the activation.
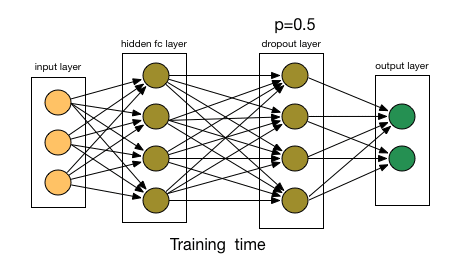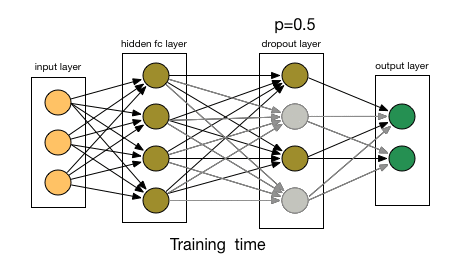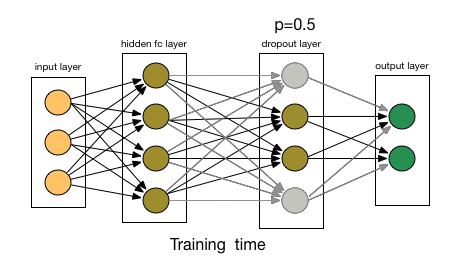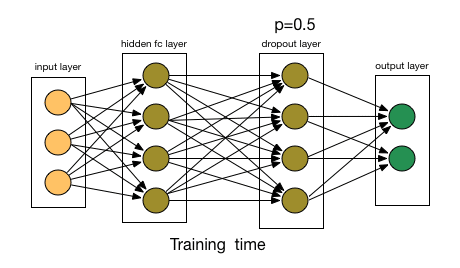
If you have to explain drop-out to a 6-year-old, this is how:
Imagine a scenario, in a classroom, a teacher asks some questions but always same two kids are answering, immediately. Now, the teacher asks them to stay quiet for some time and let other pupils participate. This way other students get to learn better. Maybe they answer wrong, but the teacher can correct them(weight updates). This way the whole class(layer) learns about a topic better.
- Dropout forces a neural network to learn more robust features that are useful in conjunction with many different random subsets of the other neurons.
- Dropout roughly doubles the number of iterations required to converge. However, training time for each epoch is less.
- With \(H\) hidden units, each of which can be dropped, we have \(2^H\) possible models.
- It can also be thought of as an ensemble technique in machine learning. Ensemble models usually perform better than a single model as they capture more randomness.
- Improving neural networks by preventing co-adaptation of feature detectors (2012)
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting (2014)
Best practices
- Apply dropout during both forward and backward propagation but disable it during testing.
- Generally, use a small dropout value of 20%-50% of neurons with 20% providing a good starting point. A probability too low has minimal effect and a value too high results in under-learning by the network.
- Use a larger network. You are likely to get better performance when dropout is used on a larger network, giving the model more of an opportunity to learn independent representations.
- Select a higher dropout rate at the (deeper) end of the network.
- With less extent dropout can also be used on incoming nodes.
- For example, immediately after the data layer or on embeddings.
DropConnect
- DropConnect is a regularization of dropout.
- DropConnect works similarly to dropout, except that it disables individual weights instead of nodes.
- It produces even more possible models, since there are almost always more connections than units.
- Results on a range of datasets show that DropConnect often outperforms Dropout.
- Regularization of Neural Networks using DropConnect (2013)
- Static DropConnect:
- Use a large number of units (\(1/p\)) in a hidden layer.
- At startup, drop weights with probability \(p\) in that layer.
- Use the same structure throughout all iterations (in contrast to DropConnect).
Early stopping
- Early stopping is a kind of cross-validation strategy where we keep one part of the training set as the validation set.
- When we see that the performance on the validation set is getting worse, we immediately stop the training on the model.
- Early Stopping - but when (1997)
Method
- Split the training data into a training set and a validation set
- Train only on the training set and evaluate the per-example error on the validation set once in a while
- Stop training as soon as the error on the validation set is higher than it was for the last time it was checked
- Use the weights the network had in that previous step as the result of the training run