Data Processing
Batch vs Stream Processing
Batch processing
- Batch processing is the processing of a large volume of data all at once.
- An efficient way to process large amounts of data that is collected over a period of time.
- Newly arriving data elements are collected into a group.
- The whole group is then processed at a future time.
- Features:
- Has access to all data.
- Might compute something big and complex.
- Has latency measured in minutes or more.
- More concerned with throughput (big data) than latency (fast response)
$$\text{Throughput}=\frac{\text{QueueSize}}{\text{Latency}}$$
- Best suited when:
- The data has already been collected.
- Processing needs multiple passes through the data.
- The data has random access.
- Dealing with large volumes of data.
- Requires all the data needed for the batch to be loaded into some storage.
- Traditional DWH and Hadoop are two common examples of systems focused on batch processing.
Stream processing

- Some data naturally comes as a never ending stream of events.
- Most continuous data series are time series data (e.g. IoT data)
- Given a sequence of data, a series of operations is applied to each element in the stream.
- Features:
- Continuous computation happens as data flows through the system.
- Computes a function of one data element, or a smallish window of recent data.
- Computes something relatively simple.
- Needs to complete each computation in near-real-time (probably seconds at most)
- Computations are generally independent.
- Asynchronous - source of data doesn't interact with the processing.
- Best suited when:
- The event needs to be detected right away and responded to quickly.
- Approximate answers are sufficient.
- Processing can be done with single pass over the data.
- Processing has temporal locality.
- Sometimes data is huge and it is not even possible to store it.
- Stream processing can work with lot less hardware and storage than batch processing.
- Common applications include time series data and detecting patterns over time, mobile and web applications, e-commerce purchases, in-game player activity, social networks, and telemetry from connected devices.
- Comparison between Batch Processing and Stream Processing
- The Log: What every software engineer should know about real-time data's unifying abstraction
- Stream-based Architecture
Concepts
- Streaming data is data that is continuously generated by different sources at high speed.
- The data is streamed in small sizes (order of Kilobytes)
- Allows users to access the content immediately, rather than having to wait for it to be downloaded.
- The data is processed sequentially on a record-by-record basis or over sliding time windows.
- Three different times can be distinguished:
- Event time: Time at which the event actually occurred.
- Ingestion time: Time at which the event was observed in the system.
- Processing time: Time at which the event was processed by the system.
- Window is the time period over which aggregations are made in stream processing.
- Tumbling window: Non-overlapping, fixed time segments.
- Sliding window: Overlapping, fixed time segments.
- Session window: Non-overlapping time segments of different length.
Approaches
- Micro-batching (Spark Streaming, Storm Trident):
- Collects the incoming data for a certain time (1–30s) and then processes it together.
- Throughput is high as processing and checkpointing will be done in one shot.
- The handling of errors is somewhat easier.
- But increases latency and efficient state management will be a challenge to maintain.
- A native streaming approach:
- Incoming data is processed directly.
- A very high throughput can now also be achieved by native streaming frameworks.
- They also offer more flexibility for windows and states.
Framework requirements
- The streaming frameworks are designed with infinite data sets in mind.
- Any technology needs to be highly scalable, capable of starting and stopping without losing information, and able to interface with messaging technologies with capabilities similar to Kafka.
- Applications are defined by how well the framework controls streams, state, and time.
- Delivery guarantees:
- At-least-once: every record is processed, but some may be processed more than once.
- At-most-once: no record will be processed more than once, but some records may be lost.
- Exactly-once: will be processed one and exactly one time even in case of failures.
- For example, in financial examples such as credit card transactions, unintentionally processing an event twice is bad. But, for instance, if the consumer uses messages to simply write (and never overwrite) a value in a database, then receiving a message more than once is no different than receiving it exactly once.
- Fault tolerance:
- In case of failures, it should recover and start processing again from the point where it left.
- This is achieved through checkpointing the state to some persistent storage from time to time.
- State management:
- Should provide a mechanism to preserve state information.
- Any non-trivial application requires a state in which previous events are stored (temp).
- Performance:
- Latency should be minimal while throughput should be maximal (hard to achieve)
- Advanced features:
- Event-time processing, watermarks, windowing
- A window is used to aggregate and analyze data for a specific period of time.
- Tumbling window: Non-overlapping, fixed time segments
- Sliding window: Overlapping, fixed time segments
- Session window: Non-overlapping time segments of different length.
- Maturity:
- The framework is already proven and battle-tested at scale by big companies.
- Choose Your Stream Processing Framework
- Distributed Stream Processing Frameworks for Fast & Big Data
Architectures
Lambda architecture
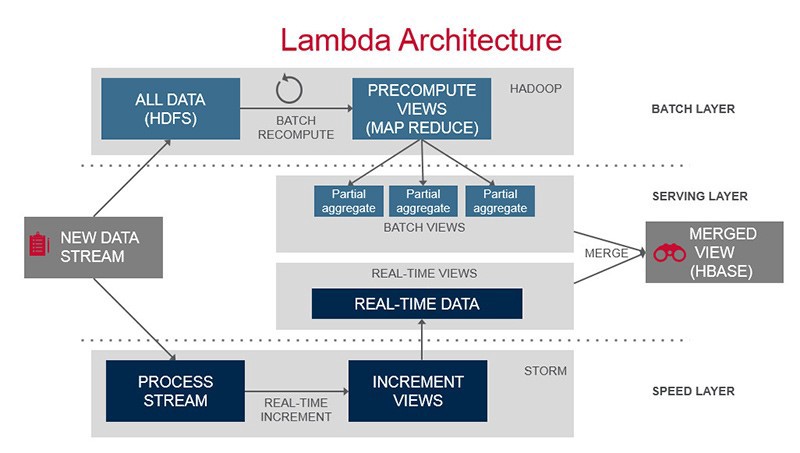
- The data entering the system is dispatched to both the batch and speed layer for processing.
- The batch layer looks at the entire data and corrects the data in the stream layer.
- Manages the master dataset (an immutable, append-only set of raw data)
- Pre-computes the batch views.
- Run using a predefined schedule (1-2x/day)
- For example, Hadoop is the de facto standard batch-processing system.
- The stream layer processes the data in real time.
- Only deals with recent data.
- Compensates for the high latency of updates to the serving layer.
- Sacrifices throughput as it aims to minimize latency by providing real-time views.
- The views may be incomplete but can be replaced by the batch layer's views later on.
- The serving layer responds to ad-hoc queries by returning precomputed views.
- Indexes the batch views so that they can be queried in low-latency basis.
- For example, Apache Druid provides a single cluster to handle output from both layers.
- Any incoming query can be answered by merging results from batch and real-time views.
- Apache Spark can be considered as an integrated solution for all layers.
- Lambda architecture
- A brief introduction to two data processing architectures
Kappa architecture
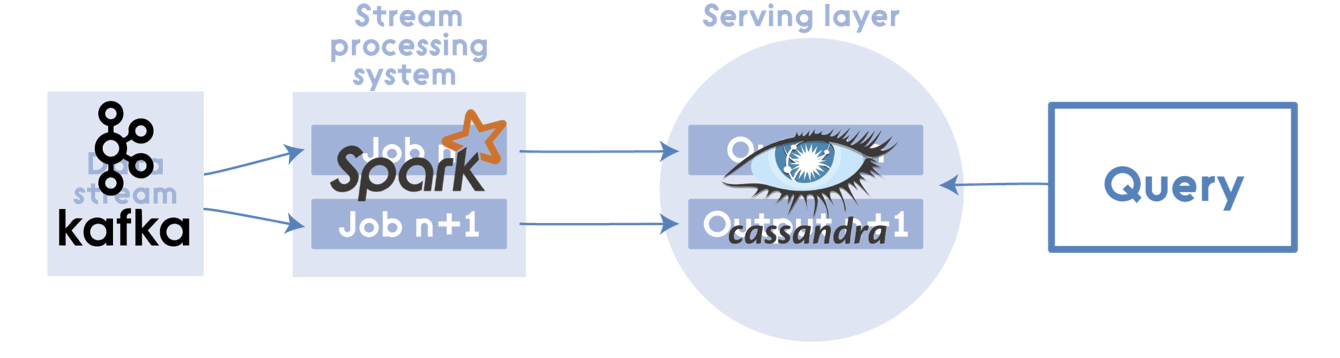
- Kappa Architecture is a software architecture pattern.
- The canonical data store in a Kappa Architecture system is an append-only immutable log.
- From the log, data is streamed through a computational system and fed into stores for serving.
- Same as Lambda Architecture system but:
- Makes all the processing happen in a near–real-time streaming mode.
- Eliminates batch processing systems entirely.
- Re-computation on historical data in the long-term storage is still possible.
- What is Kappa Architecture?
- Questioning the Lambda Architecture
Hadoop MapReduce
- MapReduce is a programming model and runtime for processing large data-sets (in clusters).
- Divides the data up into partitions that are MAPPED (transformed) and REDUCED (aggregated).
- In the map step, each data is analyzed and converted into a (key, value) pair. Then these key-value pairs are shuffled across the cluster so that all keys are on the same machine. In the reduce step, the values with the same keys are combined together.
- Google published MapReduce paper in 2004 at OSDI.
- As the processing component, MapReduce is the heart of Apache Hadoop.
- Typically the compute nodes and the storage nodes are the same.
- MapReduce sits on top of YARN.
- MapReduce = functional programming meets distributed processing.
- Computation as application of functions
- Programmer specifies only “what” (declarative programming)
- System determines “how”
- MapReduce is resilient to failures.
- The execution framework:
- Scheduling: assigns workers to map and reduce tasks.
- Data distribution: moves processes to data.
- Synchronization: gathers, sorts, and shuffles intermediate data.
- Errors and faults: detects worker failures and restarts.
- MapReduce is natively Java.
- Streaming allows interfacing to other languages such as Python.
- Use cases:
- One-iteration algorithms are perfect fits (Naive Bayes, kNN)
- Multi-iteration algorithms may be slow (K-Means)
- Algorithms that require large shared data with lots of synchronization are not good fits (SVM)
- Drawbacks:
- MapReduce writes intermediate results to disk.
- Too low level: Manual programming of per record manipulation.
- Nothing new: Map and reduce are classical Lisp or higher order functions.
- Low per node performance: Due to replication, data transfer, shuffle, and a lot of I/O to DFS.
- Not designed for incremental/streaming tasks.
Stages
- The MapReduce framework operates exclusively on key/value pairs.
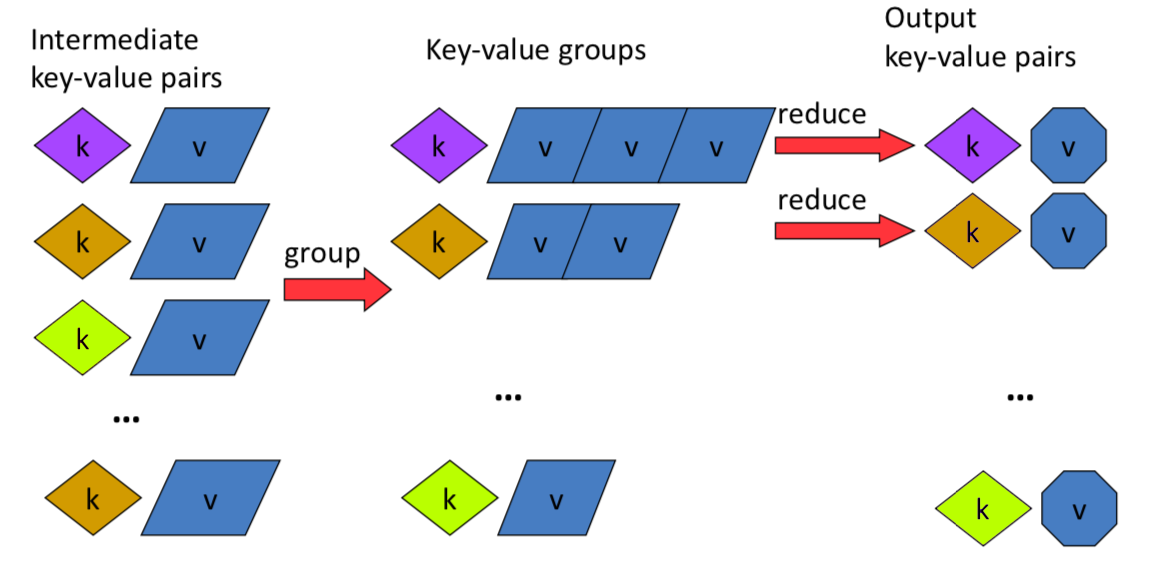
- Map:
- Mapper maps input key/value pairs to a set of intermediate key/value pairs.
- Master program divides up tasks based on location of data (same machine or at least same rack)
- Runs in parallel.
- Combine (optional):
- Can save network time by pre-aggregating at mapper.
- For associative operations like sum, count, max.
- Decreases size of intermediate data.
- Shuffle and sort:
- Different mappers may have output the same key.
- Reduce phase can’t start until map phase is completely finished.
- Shuffle is the process of moving map outputs to the reducers.
- While map-outputs are being fetched, they are merged and sorted.
- Partition:
- Partitioner partitions the key space.
- All values with the same key need to be sent to the same reducer.
- Usually, system distributes the intermediate keys to reduce workers “randomly”.
- Reduce:
- Reducer combines all intermediate values for a particular key.
- If some workers are slow (Straggler problem), start redundant workers and take the fastest one.
- Runs in parallel.
- MapReduce Tutorial
# Example: Break down movie ratings by rating score
from mrjob.job import MRJob
from mrjob.step import MRStep
class RatingsBreakdown(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper_get_ratings,
reducer=self.reducer_count_ratings)
]
def mapper_get_ratings(self, _, line):
(userID, movieID, rating, timestamp) = line.split('\t')
yield rating, 1
def reducer_count_ratings(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
RatingsBreakdown.run()
# Example: Running this example
# Local mode
$ python RatingsBreakdown.py u.data
# On Hadoop
$ python RatingsBreakdown.py -r hadoop --hadoop-streaming-jar $HADOOP_HOME/hadoop-streaming.jar u.data
Apache Tez

- Apache Tez expresses complex computations in MapReduce programs as DAGs.
- Improves the MapReduce paradigm by dramatically improving its speed.
- Permits dynamic performance optimizations:
- Eliminates unnecessary steps and dependencies.
- Optimizes physical data flows and resource usage.
- Integrates well with Pig, Hive and other engines (can be selected via checkbox)
- Apache Tez can only perform interactive processing.
- Apache Tez: Overview
Apache Spark
- Apache Spark is an open-source distributed general-purpose cluster-computing framework.
- Originated as a university-based project developed at UC Berkeley’s AMPLab in 2009.
- Then donated the Apache Software Foundation in 2013.
- Provides an interface for programming clusters with implicit data parallelism and fault tolerance.
- Can perform batch, stream, interactive and graph processing.
- Runs applications on Hadoop up to 100x faster in memory and 10x faster on disk.
- Offers real-time computation and low latency because of in-memory computation.
- Makes accessing stored data quickly by keeping data in servers' RAM.
- Achieves high performance using DAGScheduler, query optimizer, and physical execution engine.
- Simple programming layer provides powerful caching and disk persistence capabilities.
- Spark is a polyglot:
- Supports Scala, Python, R, and SQL programming languages.
- Runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud.
- Can access data in HDFS, Cassandra, HBase, Hive, and other data sources.
- Spark on cloud offers faster time to deployment, better availability, more frequent feature updates, more elasticity, more geographic coverage, and lower costs linked to actual utilization.
- Limitations:
- Spark is near real-time processing of live data: it operates on micro-batches of records. Native streaming tools such as Storm, Apex, or Flink are more suitable for low-latency applications. Flink and Apex can also be used for batch computation.
- Currently, Spark only supports ML algorithms that scale linearly with the input data size.
- Does not have its own file management system.
- Requires lots of RAM to run in-memory and thus is expensive.
- Not a good fit for small datasets, there are other tools which are preferred:
- AWK - a command line tool for manipulating text files.
- R - a programming language and software environment for statistical computing.
- PyData Stack, which includes pandas, matplotlib, numpy, and scikit-learn among other libraries.
- Use pandas by chunking and filtering the data, and writing out the relevant parts to disk.
- Use libraries such as SQLAlchemy, to leverage pandas and SQL simultaneously.
Compared to MapReduce
- The Hadoop ecosystem is a slightly older technology than the Spark ecosystem.
- MapReduce is slower than Spark because it writes data out to disk during intermediate steps.
- While Spark is great for iterative algorithms, Hadoop MapReduce is good at batch processing.
- Many big companies, such as Facebook and LinkedIn, are still running on Hadoop.
- Migrating legacy code from Hadoop to Spark might not be worth the cost.
- Spark runs up to 100 times faster than Hadoop MapReduce for large-scale data processing.
"Spark is beautiful. With Hadoop, it would take us six-seven months to develop a machine learning model. Now, we can do about four models a day.”
Architecture
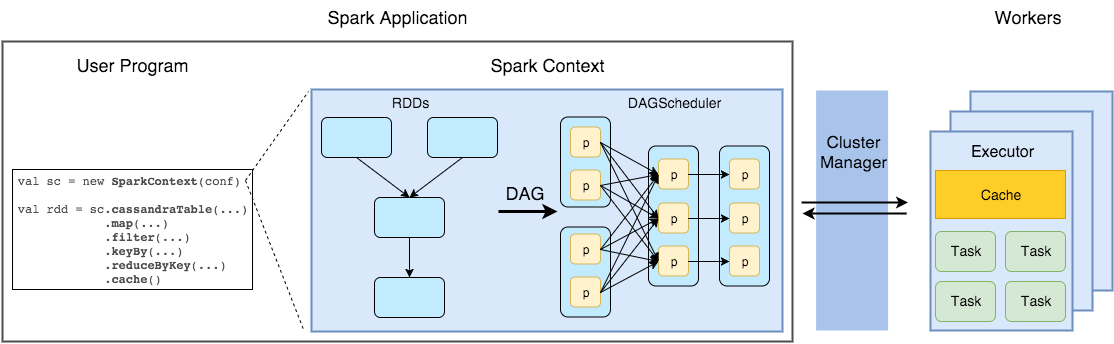
- Apache Spark Framework uses a master–slave architecture.
- Master node:
- Driver: Schedules the job execution and negotiates with the cluster manager.
- SparkContext (
scvariable): Represents the connection to the Spark cluster. Creates RDDs. After Spark 2.0, SparkSession (sparkvariable) combines SparkContext, SQLContext, and HiveContext. Creates DataFrames. - DAGScheduler: Computes a DAG of stages for each job and submits them to TaskScheduler.
- TaskScheduler: Sends tasks to the cluster, runs them, and retries if there are failures.
- SchedulerBackend: Allows plugging in different implementations (Mesos, YARN, Standalone)
- Cluster manager:
- Either Spark’s own standalone cluster manager, Mesos, YARN or Kubernetes.
- Slave node (Executor):
- Executor is a distributed agent responsible for the execution of tasks.
- Stores the computation results data in memory, on disk or off-heap.
- Interacts with the storage systems.
- Cluster Mode Overview
- Apache Spark: Differences between client and cluster deploy modes
- Apache Spark: core concepts, architecture and internals
DAGs
- MapReduce forces a particular linear dataflow structure on distributed programs.
- Each MapReduce operation is independent and Hadoop has no idea which one comes next.
- The limitations of MapReduce in Hadoop became a key point to introduce DAG in Spark.
- Spark forms a DAG of consecutive computation stages.
- Allows the execution plan to be optimized, e.g. to minimize shuffling data around.
- DAG (Directed Acyclic Graph) is a finite directed graph with no directed cycles.
- A set of vertices and edges, where vertices represent RDDs and edges represent transformations.
- When an action is called on RDD at a high level, DAG is created and submitted to the DAGScheduler.
- DAGScheduler is the scheduling layer that implements stage-oriented scheduling.
- Transforms a logical execution plan (GAD) into a physical execution plan (stages of tasks)
- The narrow transformations will be grouped (pipelined) together into a single stage.
- There are two transformations that can be applied onto RDDs:
- Narrow transformations: Stages combine tasks which don’t require shuffling/repartitioning of the data (e.g., map, filter). The stages that are not interdependent may be executed in parallel.
- Wide transformations: Require shuffling and result in stage boundaries.
- The DAGScheduler will then submit the stages to the TaskScheduler.
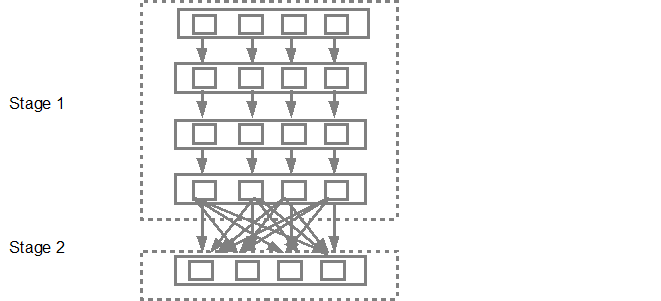
Programming model
RDD API
- The RDD APIs have been on Spark since the 1.0 release.
- RDD is a read-only multiset of data items distributed over a cluster of machines.
- Resilient: Fault tolerant and transformations can be repeated in the event of data loss.
- Distributed: Distributed data among the multiple nodes in a cluster.
- Dataset: Collection of partitioned data with values.
- MapReduce operations:
- RDD uses MapReduce operations which are widely adopted for processing.
- Immutable:
- RDDs composed of a collection of records which are partitioned.
- A partition is a basic unit of parallelism in an RDD.
- Each partition is one logical division of data which is immutable.
- Immutability helps to achieve consistency in computations.
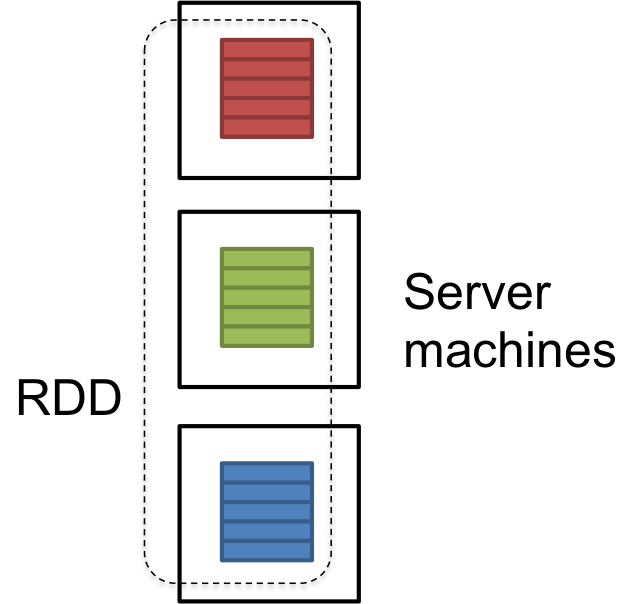
- Fault tolerant:
- Fault-tolerance is achieved by keeping track of the "lineage" of each RDD: each RDD maintains a pointer to one or more parents and metadata about the relationship.
- Rather than doing data replication, computations can be reconstructed in case of data loss.
- This saves effort in data management and replication and thus achieves faster computation.
- Lazy evaluations:
- The transformations are only computed when an action requires a result to be returned.
- Support two types of operations:
- Transformations: Create a new RDD from an existing RDD.
- Actions: Return a value to the driver program after running a computation on the RDD.
- They apply to the whole RDD not on a single element.
- The original RDD remains unchanged throughout.
- Can easily and efficiently process data which is structured as well as unstructured data.
- Can be created by parallelizing a collection or referencing a dataset in an external storage system.
- Remain in memory, greatly increasing the performance of the cluster.
- Only spilling to disk when required by memory limitations.
- Supports persisting in memory or on disk, or replicating across multiple nodes.
- Persisting in memory with
persistallows future actions to be (often 10x) faster.
- Cons:
- Does not support compile-time safety for both syntax and analysis errors.
- RDDs don’t infer the schema of the ingested data.
- Cannot take advantage of the catalyst optimizer and Tungsten execution engine.
DataFrame API (Untyped)
- Spark introduced DataFrames in Spark 1.3 release.
- A DataFrame is organized into named columns.
- It is conceptually equivalent to a table in a relational database.
- Allows running SQL queries.
- DataFrame is a distributed collection of Row objects:
- DataFrame is simply a type alias of Dataset[Row].
- Row is a generic untyped JVM object.
- Hive compatibility:
- One can run unmodified Hive queries on existing Hive warehouses.
- Reuses Hive frontend and MetaStore and gives full compatibility.
- Along with Dataframe, Spark also introduced Catalyst optimizer.
- Catalyst contains a general library for representing trees and applying rules to manipulate them.
- Supports both rule-based and cost-based optimization.
- Tungsten:
- Tungsten provides a physical execution backend which explicitly manages memory and dynamically generates bytecode for expression evaluation.
- Pros:
- Expression-based operations and UDFs
- Logical plans and optimizer
- Fast/efficient internal representation
- Well-defined schema leads to a more efficient storage
- Read and write to JSON, Hive, Parquet
- Communicates with JDBC/ODBC, Tableau
- Cons:
- Does not support compile-time safety for analysis errors (only syntax errors)
- Cannot recover domain object (e.g. Person) once transformed into DataFrame (Row)
Dataset API (Typed)
- Spark introduced Dataset in Spark 1.6 release.
- Provides best of both RDD and DataFrame.
- An extension to DataFrames that provides a type-safe, object-oriented programming interface.
- Allows to work with both structured and unstructured data.
- Datasets are dictated by a case class defined in Scala or a class in Java.
- Allows to easily convert existing RDDs and DataFrames into Datasets without boilerplate code.
- Since Python and R have no compile-time type-safety, they support only DataFrames.
- Pros:
- Best of both worlds: type safe + fast
- Cons:
- Slower than DataFrames
- Not as good for interactive analysis, especially Python
- Requires type casting to string
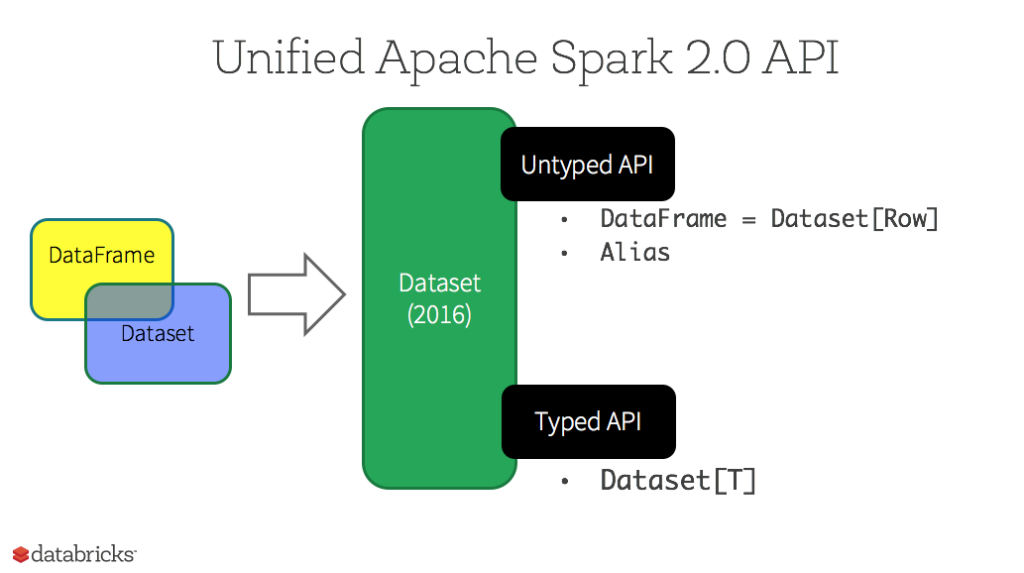
- Both DataFrames and Datasets internally do final execution on RDDs.
- Since Spark 2.0, DataFrame and Datasets APIs are unified into a single Datasets API.
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets
Components
Spark Core
- Spark Core is the base engine for large-scale parallel and distributed data processing.
- Provides distributed task dispatching, scheduling, and basic I/O functionalities.
- Centered on the RDD abstraction.
- Other libraries are built on top of this engine.
# Example: Spark Core
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split("\s+")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
Spark SQL
- Spark SQL blurs the lines between RDDs and relational tables.
- Provides a programming abstraction called DataFrames.
- Provides SQL language support, with command-line interfaces and ODBC/JDBC connections.
- Supports the open source Hive project, and its SQL-like HiveQL query syntax.
- Includes a cost-based optimizer, columnar storage, and code generation to make queries fast.
# Example: Spark SQL
df = text_file.map(lambda r: Row(r)).toDF(["line"])
text_file.select(explode(split(col("line"), "\s+"))
.alias("word"))
.groupBy("word")
.count()
Spark MLlib
- Spark MLlib is used to perform machine learning algorithms.
- These include statistics, classification and regression, collaborative filtering techniques, cluster analysis methods, dimensionality reduction techniques, feature extraction and transformation functions, and optimization algorithms.
- 9 times as fast as the disk-based implementation used by Apache Mahout.
- Scales better than Vowpal Wabbit.
# Example: Spark MLlib
df = sqlContext.createDataFrame(data, ["label", "features"])
lr = LogisticRegression(maxIter=10)
model = lr.fit(df)
model.transform(df).show()
Spark Streaming
- Spark Streaming supports scalable and fault-tolerant processing of streaming data.
- Lambda architecture comes free with Spark Streaming.
- High throughput, good for many use cases where sub-latency is not required.
- Fault tolerance by default due to micro-batch nature.
- Simple to use higher level APIs.
- Big community and aggressive improvements.
- Uses microbatching to approximate real-time stream analytics.
- Micro-batches are batches that are small and/or processed at small intervals.
- Performs RDD transformations on those mini-batches of data.
- Code written for batch analytics can be used in streaming analytics.

- Provides exactly-once guarantees more easily than a true real-time system.
- Spark DStream is a continuous stream of data.
- Listens for incoming data, collects it and generates RDDs for each time period.
- Once can access the underlying RDDs if needed.
- Discretized Streams (DStreams)
- Common stateless transformation include
map,flatMap,filterandreduceByKey. - Stateful transformations combine data across multiple batches.
- Maintain a long-lived state on a DStream, for example, for running totals.
- The state is stored locally in memory or on disk and is regularly backed up by checkpointing.
- Windowed transformations allow computations over a longer time period than mini-batches.
- One might process the data every second but aggregate the data every hour.
- The batch interval is how often the data is captured into DStream.
- The slide interval is how often the windowed transformation is computed.
- The window interval is how far back in time the windowed transformation goes.
- Structured streaming paves the way for event-based streaming in Spark (like Flink)
- Imagine a table that never ends and new data just keeps getting appended to it.
- A streaming code looks equivalent to a non-streaming code.
- Structured data representation allows for more efficiency.
- SQL-style queries allow for further query optimizations.
- Interoperability with other components such as Spark MLlib.
- Built on the Spark SQL engine.
- Structured Streaming Programming Guide
- Can integrate with established sources like Flume, Kafka, Kinesis, or TCP sockets.
# Start TCP server
$ nc -lk 9999
# Example: Display a running word count of text data received from a data server listening on a TCP socket.
# https://spark.apache.org/docs/2.2.0/structured-streaming-programming-guide.html
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()
# Running this example
$ ./bin/spark-submit examples/src/main/python/sql/streaming/structured_network_wordcount.py localhost 9999
GraphX
- GraphX is the Spark API for graphs and graph-parallel computation.
- Includes a number of widely understood graph algorithms, including PageRank.
- RDDs are immutable and thus GraphX is unsuitable for graphs that need to be updated.
- GraphX can be viewed as being the Spark in-memory version of Apache Giraph.
Addressing issues
- Insufficient resources:
- Different stages of a Spark job can differ greatly in their resource needs. Some stages might require a lot of memory, others might need a lot of CPU. Use the Spark UI and logs to collect information on these metrics.
- If running into out-of-memory errors, consider increasing the number of partitions.
- If memory errors occur over time, look into why the size of some objects is increasing.
- Look for ways of freeing up resources if garbage collection metrics are high.
- ML algorithms: The driver stores the data the workers share and update; check if the algorithm is pushing too much data there.
- Too much data to process? Compressed file formats can be tricky to interpret.
- Data skew:
- Data skew is very specific to the dataset.
- Drill down Spark UI to the task level to see if certain partitions process significantly more data than others and if they are lagging behind.
- Add an intermediate data processing step with an alternative key.
- Adjust the
spark.sql.shuffle.partitionsparameter if necessary.
- Inefficient queries:
- Use the Spark UI to check the DAG and the jobs and stages it’s built of.
- Catalyst will push filters as early as possible but won’t move them across stages. Make sure to do these optimizations manually without compromising the business logic.
- Catalyst can’t decide on its own how much data will shuffle across the cluster. Make sure to perform joins and grouped aggregations as late as possible.
- For joins, if one of dataframes is small, consider using broadcasting.
- Monitoring and Instrumentation
- Configuring Logging
- Tuning Spark
- Performance Tuning
Apache Storm
- Apache Storm is an open source, scalable, fault-tolerant, distributed real-time computation system.
- Did for realtime processing what Hadoop did for batch processing.
- Has continued to evolve since it became a top-level Apache project.
- Features:
- Integrates: integrates with any queueing system and any database system.
- Fast: benchmarked as processing one million 100 byte messages per second per node.
- Scalable: with parallel calculations that run across a cluster of machines.
- Fault-tolerant: when workers die, Storm will automatically restart them.
- Reliable: guarantees that each tuple will be processed at least once or exactly once.
- Easy to operate: standard configurations are suitable for production on day one.
- Reliably processes unbounded streams of data... without storing any actual data.
- Can process a million tuples per second per node.
- Has a "local mode" where a Apache Storm cluster is simulated in-process.
- Can be used with any programming language thanks to Thrift.
- Used for realtime analytics, online ML, continuous computation, distributed RPC, ETL.
- Kafka + Storm seems to be a pretty popular combination.
Compared to Apache Spark
- Spark performs data-parallel computations while Storm performs task-parallel computations.
- Spark supports "exactly once" processing mode only.
- Storm provides better latency (truly real-time processing) with fewer restrictions.
- Storm offers "tumbling" windows (5s every 5s) in addition to "sliding" windows (5s every 2s)
- With Spark, the same code can be used for both batch and stream processing.
- Spark is offered by a dedicated company - Databricks - for support.
- Both can be allocated on the same cluster.
Architecture
- A Storm cluster is superficially similar to a Hadoop cluster.
- Whereas on Hadoop you run "MapReduce jobs", on Storm you run "topologies".
- MapReduce job eventually finishes, whereas a topology processes messages forever until killed.
- A running topology consists of many worker processes spread across many machines.
- Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes.
- Each node in a Storm topology executes in parallel (tunable)
- Will automatically reassign any failed tasks.
- Guarantees that there will be no data loss, even if machines go down and messages are dropped.
- There are two kinds of nodes on a Storm cluster: the master node and the worker nodes.
- All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster.
- Storm nodes are fail-fast and stateless: all state is kept in Zookeeper or on local disk.
- This design leads to Storm clusters being incredibly stable.
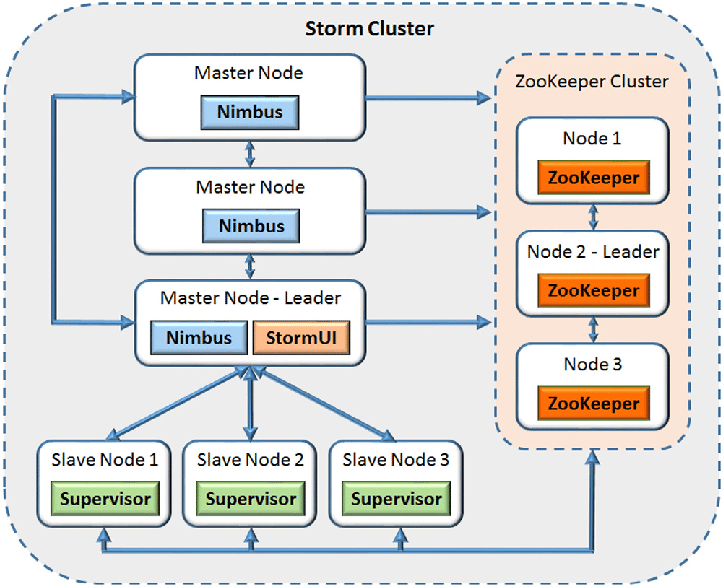
- The master node runs a daemon called "Nimbus":
- Responsible for distributing tasks to machines and monitoring for failures.
- Similar to Hadoop's "JobTracker".
- Each worker node runs a daemon called the "Supervisor":
- Starts and stops worker processes as necessary based on Nimbus instructions.
- Each worker process executes a subset of a topology.
Concepts
- A stream is an unbounded sequence of tuples.
- A tuple is a named list of values, and a field in a tuple can be an object of any type.
- For example, a “4-tuple” might be
(7, 1, 3, 7)
- Storm provides the primitives "spouts" and "bolts" for transforming a stream into a new stream.
- Storm defines its workflows in DAGs called “topologies”:
- An arbitrarily complex multi-stage stream computation out of spouts and bolts.
- The top-level abstraction that are submitted to Storm clusters for execution.
- Runs forever, or until killed.
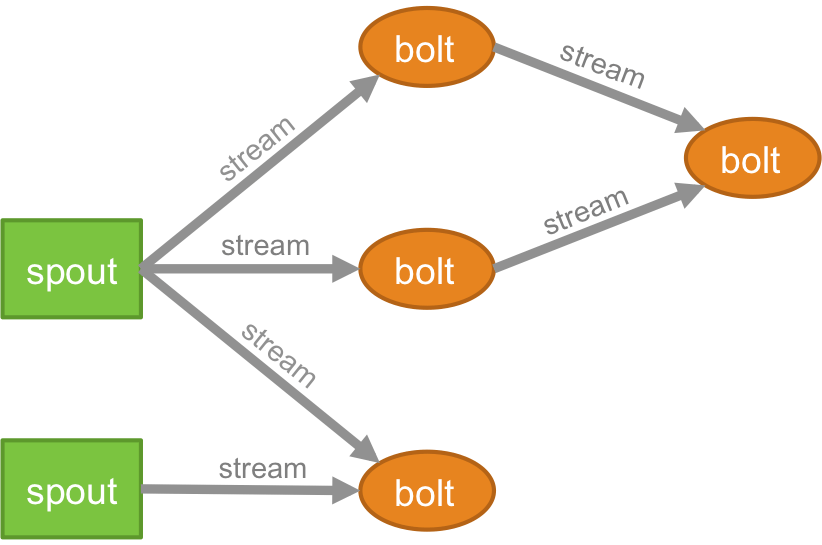
- A spout is a source of streams in a computation.
- Typically a spout reads from a queueing broker such as Kafka.
- A bolt processes any number of input streams and produces any number of new output streams.
- Most of the logic of a computation goes into bolts.
- Run functions, filter tuples, do streaming aggregations and joins, talk to databases.
- Complex stream transformations require multiple steps and thus multiple bolts.
- Each task corresponds to one thread of execution at spout or bolt.
- A stream grouping defines how to send tuples from one set of tasks to another set of tasks.
- Shuffle: Sends tuples in random (to distribute work evenly across receiving tasks)
- Fields: Sends tuples based on one or more fields in the tuple (for segmentation)
- All: Sends a single copy of each tuple to all instances (for signals)
- Developing Apache Storm Applications
Components
- Storm applications are usually written in Java.
- Although bolts may be directed through scripts in different languages (thanks to Thrift)
Storm Core
- Storm Core guarantees that every event will be processed "at least once".
- The lower-level API for Storm.
- Messages are only replayed when there are failures.
// Example: A simple bolt class
// https://storm.apache.org/releases/2.0.0/Tutorial.html
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
// Example: A simple topology
// https://storm.apache.org/releases/2.0.0/Tutorial.html
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1");
Trident
- Trident guarantees that every event will be processed "exactly once".
- Higher-level API for Storm.
- An abstraction built on top of Storm which allows stateful stream processing.
- Provides "transactional" datastore persistence.
- Has joins, aggregations, grouping, functions, and filters.
- Adds complexity to a Storm topology, lowers performance and generates state.
- Trident is similar to high level batch processing tools like Pig or Cascading.
- Processes the stream as small batches of tuples.
- Provides functions for doing aggregations across batches and persistently storing them.
- Exactly-Once Processing with Trident - The Fake Truth
// Example: Trident
// https://storm.apache.org/releases/2.0.0/Trident-tutorial.html
// Create a spout that generates an infinite stream of sentences
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);
// Compute streaming word count from an input stream of sentences
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
- Stream APIs is another alternative interface to Storm (experimental)
- Provides a typed API for expressing streaming computations.
- Supports functional style operations such as map-reduce.
// Example: A word count topology expressed using the Stream API
// https://storm.apache.org/releases/2.0.0/Stream-API.html
StreamBuilder builder = new StreamBuilder();
builder
// A stream of random sentences with two partitions
.newStream(new RandomSentenceSpout(), new ValueMapper<String>(0), 2)
// a two seconds tumbling window
.window(TumblingWindows.of(Duration.seconds(2)))
// split the sentences to words
.flatMap(s -> Arrays.asList(s.split(" ")))
// create a stream of (word, 1) pairs
.mapToPair(w -> Pair.of(w, 1))
// compute the word counts in the last two second window
.countByKey()
// print the results to stdout
.print();
Storm SQL
- The Storm SQL integration allows to run SQL queries over streaming data in Storm (experimental)
- Allows faster development cycles on streaming analytics.
- Unifies batch data processing like Apache Hive and real-time streaming data analytics.
- Compiles SQL queries to Storm topologies leveraging Streams API.
-- Example: Filtering Kafka Stream
-- https://storm.apache.org/releases/2.0.0/storm-sql.html
CREATE EXTERNAL TABLE ORDERS (ID INT PRIMARY KEY, UNIT_PRICE INT, QUANTITY INT) LOCATION 'kafka://orders?bootstrap-servers=localhost:9092,localhost:9093'
CREATE EXTERNAL TABLE LARGE_ORDERS (ID INT PRIMARY KEY, TOTAL INT) LOCATION 'kafka://large_orders?bootstrap-servers=localhost:9092,localhost:9093' TBLPROPERTIES '{"producer":{"acks":"1","key.serializer":"org.apache.storm.kafka.IntSerializer"}}'
INSERT INTO LARGE_ORDERS SELECT ID, UNIT_PRICE * QUANTITY AS TOTAL FROM ORDERS WHERE UNIT_PRICE * QUANTITY > 50
# Example: Running StormSQL
$ bin/storm sql order_filtering.sql order_filtering --artifacts "org.apache.storm:storm-sql-kafka:2.0.0-SNAPSHOT,org.apache.storm:storm-kafka-client:2.0.0-SNAPSHOT,org.apache.kafka:kafka-clients:1.1.0^org.slf4j:slf4j-log4j12"
Apache Flink
- Apache Flink is a framework and distributed processing engine for stateful streaming computations.
- Flink means “agile or swift” in German.
- Originated as a joint effort of several German and Swedish universities.
- Entered incubation as an Apache project in 2015.
- Was as inspired by Google Data Flow model.
- A unified framework which allows data workflows for streaming, batch, SQL and Machine learning.
- Provides a high-throughput, low-latency streaming engine.
- Supports native streaming, that is, "message at a time" stream processing.
- Supports event-time processing (as opposed to processing time)
- Has an impressive windowing system.
- Event-time, highly customizable window logic, and fine-grained control of time.
- Features a library for Complex Event Processing (CEP) to detect patterns in data streams.
- This + real-time streaming + exactly-one semantics is important for financial apps.
- Event time processing in Apache Spark and Apache Flink
- Supports execution of bulk/batch and stream processing programs.
- Can operate over unbounded and bounded (fixed-size) data streams.
- Can handle real streams and recorded streams.
- Treats batch as a special example of streaming.
- Supports the execution of iterative algorithms natively.
- Supports sophisticated state management.
- Supports exactly-once consistency guarantees for state.
- Can to run in common cluster environments, perform computations at in-memory speed and any scale.
- Can be deployed on YARN, Apache Mesos, and Kubernetes but also as stand-alone cluster on bare-metal hardware.
- Configured for high availability, Flink does not have a single point of failure.
- Has been proven to scale to 1000s of nodes and terabytes of application state.
- Stateful Flink applications are optimized for local, in-memory state access.
- Can survive failures while still guaranteeing exactly-one semantics.
- Provides a lightweight fault tolerance mechanism based on distributed checkpoints.
- A checkpoint is an automatic, asynchronous snapshot of the state of an application.
- Can write checkpoints to a custom persistent storage.
- Includes a mechanism of savepoints:
- The user can stop a running Flink program and then resume it from the same position.
- Programs can be written in Java, Scala, Python, and SQL.
- Automatically compiled and optimized into dataflow programs.
- Doesn’t ship with a storage system - it is just a computation engine.
- Provides a rich set of connectors such as Kafka, Kinesis, Elasticsearch, and JDBC.
- Getting widely accepted by big companies at scale like Uber, Alibaba, CapitalOne.
- What is Apache Flink? — Applications
Use cases
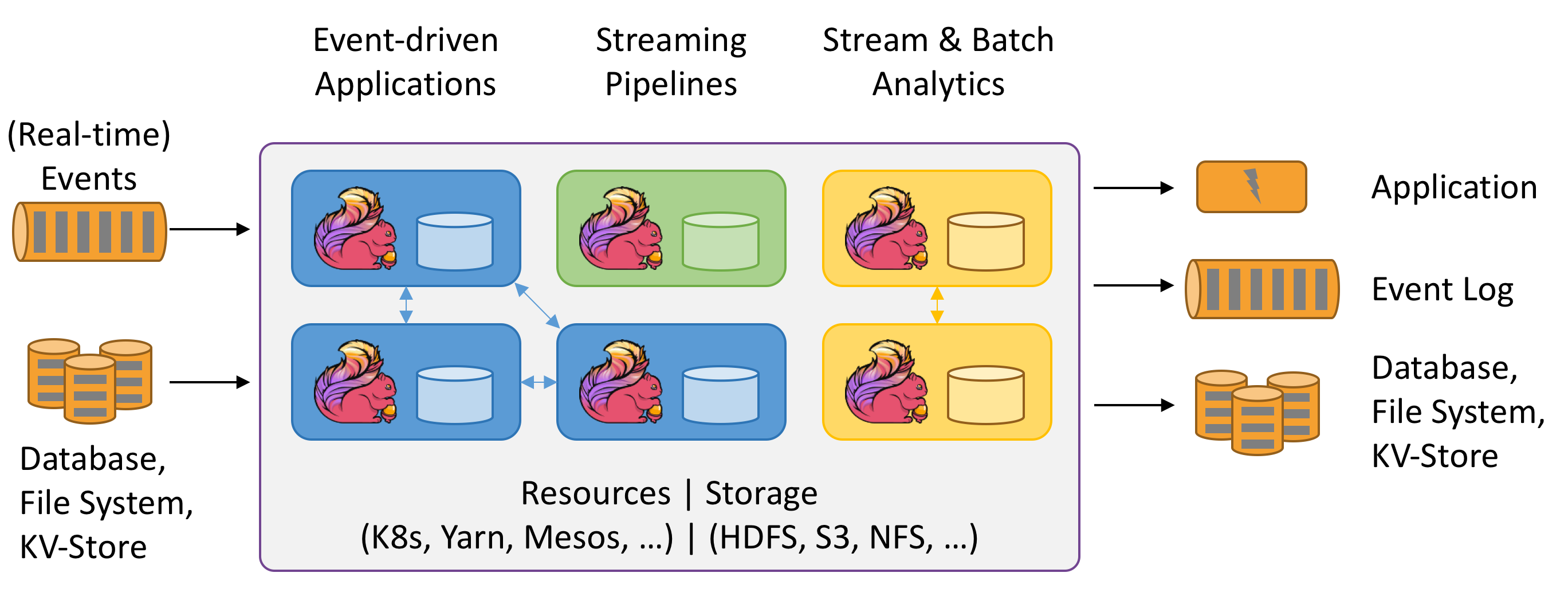
- Event-driven applications:
- Reacts to incoming events by triggering computations, state updates, or external actions.
- Data and computation are co-located in Flink.
- Use cases: Fraud and anomaly detection, rule-based alerting, business process monitoring.
- Data analytics applications:
- Analytics can be performed in a real-time fashion.
- SQL queries compute the same result regardless of recorded events or streaming events.
- Rich support for UDFs ensures that custom code can be executed in SQL queries.
- Use cases: Ad-hoc analysis of live data.
- Data pipeline applications:
- Data pipelines operate in a continuous streaming mode instead of being periodically triggered.
- The obvious advantage over periodic ETL jobs is the reduced latency of moving data.
- Use cases: Continuous ETL in e-commerce.
- Apache Flink - Use Cases
- High-throughput, low-latency, and exactly-once stream processing with Apache Flink
Compared to other frameworks
- Leader of innovation in open-source streaming landscape.
- Looks like a true successor of Storm.
- Slightly younger than Spark, but is gaining in popularity.
- Compared to other frameworks, there is no micro batching of data but true streaming.
- Can process data based on event times, not processing times.
- Has its own rocketing ecosystem where it directly competes with Spark.
- In Search of Data Dominance: Spark Versus Flink
- Stream-based Architecture
- Choose Your Stream Processing Framework
Components
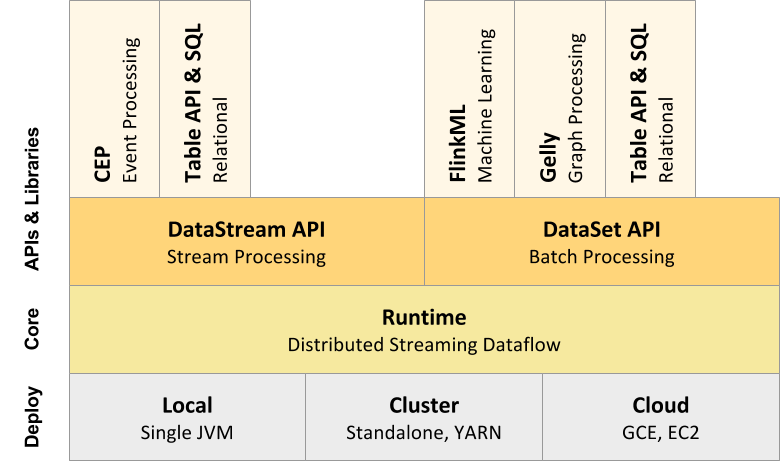
- Has a layered architecture where each component is a part of a specific layer.
- Each layer is built on top of the others for clear abstraction.
- Flink’s basic data model is comprised of data streams, i.e., sequences of events.
- A stream can be an infinite stream that is boundless.
- A stream can also be a finite stream with boundaries (equivalent to batch processing)
- Upon execution, Flink programs are mapped to streaming dataflows.
- Starts with one or more sources (a data input)
- Ends with one or more sinks (a data output)
- Can be arranged as a DAG, allowing an application to branch and merge dataflows.
- General Architecture and Process Model
- Chapter 3. The Architecture of Apache Flink
DataStream API
- DataStream API enables transformations on unbounded streams of data.
- Provides primitives for many common stream processing operations, such as windowing, record-at-a-time transformations, and enriching events by querying an external data store.
- Based on provided functions, such as map, reduce, and aggregate, and UDFs.
- Flink DataStream API Programming Guide
// Example: Count the words coming from a web socket in 5 second windows
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindowWordCount {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
counts.print
env.execute("Window Stream WordCount")
}
}
# Start the input stream with netcat
$ nc -lk 9999
DataSet API
- DataSet API enables transformations on bounded data sets.
- The primitives include map, reduce, (outer) join, co-group, and iterate.
- Operations are backed by algorithms and data structures that operate on serialized data.
- Flink DataSet API Programming Guide
// Example: Count works locally
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
counts.print()
}
}
Table API and SQL
- Table API is a SQL-like expression language for relational stream and batch processing.
- Can be easily embedded in Java and Scala DataStream and DataSet APIs.
- Tables can be created from external sources or from existing DataStreams and DataSets.
- Supports relational operators such as selection, aggregation, and joins.
// Example: Perform join on two tables
case class MyResult(a: String, d: Int)
val input1 = env.fromElements(...).toTable(tEnv).as('a, 'b)
val input2 = env.fromElements(...).toTable(tEnv, 'c, 'd)
val joined = input1.join(input2)
.where("a = c && d > 42")
.select("a, d")
.toDataSet[MyResult]
- The highest-level language supported by Flink is SQL.
- Semantically similar to the Table API and represents programs as SQL query expressions.
- Tables can be queried with regular SQL if registered.
- Current version (1.9.0) only supports SELECT, FROM, WHERE, and UNION clauses.
// Example: Executing a SQL query on a streaming table
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
// read a DataStream from an external source
val ds: DataStream[(Long, String, Integer)] = env.addSource(...)
// register the DataStream under the name "Orders"
tableEnv.registerDataStream("Orders", ds, 'user, 'product, 'amount)
// run a SQL query on the Table and retrieve the result as a new Table
val result = tableEnv.sql(
"SELECT STREAM product, amount FROM Orders WHERE product LIKE '%Rubber%'")
- Both interfaces operate on a relational Table abstraction.
- Both interfaces offer equivalent functionality and can be mixed in the same program.
- Leverage Apache Calcite for parsing, validation, and query optimization.
- Table API and SQL Beta