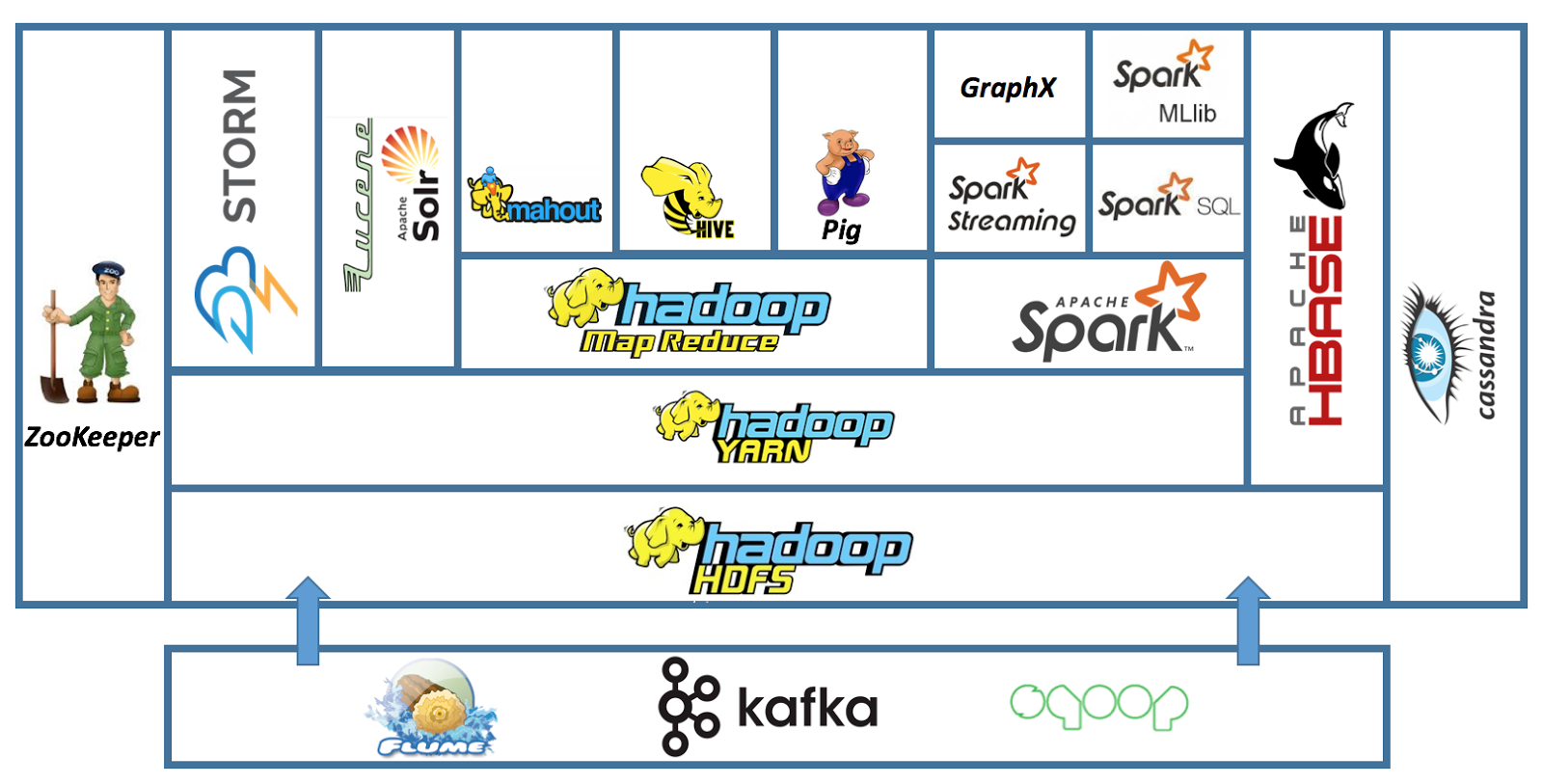
Hadoop is an open-source platform for distributed storage and processing of very large datasets.
Although Hadoop is best known for MapReduce and its distributed filesystem (HDFS), the term is also used for a family of related projects that fall under the umbrella of infrastructure for distributed computing and large-scale data processing.
Most of the core projects are hosted by the Apache Software Foundation.
As the Hadoop ecosystem grows, more projects are appearing, not necessarily hosted at Apache, which provide complementary services to Hadoop.
The Hadoop framework itself is mostly written in the Java programming language.
Hadoop requires Java Runtime Environment (JRE)
Hadoop can be deployed in a traditional onsite datacenter as well as in the cloud (fully-managed)
A number of companies offer commercial implementations or support for Hadoop.
Components
The term Hadoop is often used for both base modules and sub-modules and also the ecosystem.
The base Apache Hadoop framework is composed of the following modules:
Hadoop Common: contains libraries and utilities needed by other Hadoop modules.
Hadoop Distributed File System (HDFS): a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster.
Hadoop YARN (introduced in 2012): a platform responsible for managing computing resources in clusters and using them for scheduling users' applications.
Hadoop MapReduce: an implementation of the MapReduce programming model for large-scale data processing.