Data Storage
HDFS

- The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware (GNU/Linux).
- Originally built as infrastructure for the Apache Nutch web search engine.
- Takes as its design guides elements from Google File System (GFS).
- HDFS is highly fault tolerant, available, reliable and scalable.
- Accommodation of large data sets:
- A typical file in HDFS is gigabytes to terabytes in size.
- It stores each file as a sequence of blocks (typically 128MB)
- A file once created, written, and closed need not be changed.
- HDFS uses client side caching to improve performance.
- Fast recovery from hardware failures:
- HDFS has been built to detect faults and automatically recover quickly.
- The blocks of a file are replicated for fault tolerance (configurable by the replication factor)
- Files in HDFS are write-once and have strictly one writer at any time.
- High availability:
- This redundancy offers higher availability and data locality for efficient computation.
- Large Hadoop clusters are arranged in racks (network traffic within desirable)
- Access to streaming data:
- HDFS is intended more for batch processing versus interactive use.
- High bandwidth more important than low latency.
- Portability:
- HDFS is designed to be portable across multiple hardware platforms.
- Built using the Java language.
- Use cases:
- MapReduce kind of workloads, similar to GFS.
- Ideally suited for write-once and read-many times use cases.
- Hadoop Use Cases and Case Studies
- HDFS is partly POSIX-compliant.
- HDFS is at the core of many open-source data lakes.
- With Apache Hadoop 2.0 (2013), YARN resource manager was added, and MapReduce and HDFS were effectively decoupled.
- With Apache Hadoop 3.0 (2017), HDFS supports additional NameNodes, erasure coding facilities and greater data compression.
- HDFS Architecture Guide
# Example: Create a directory named /foodir
$ bin/hadoop dfs -mkdir /foodir
POSIX
- POSIX is a family of IEEE standards, specified by the , to clarify and make uniform the API provided by UNIX operating systems.
- Programs can read and write to the distributed data store as if the data were mounted locally.
- Limited POSIX compliance also extended to various versions of Windows.
- Most important things POSIX 7 defines
Compared to cloud storage (S3)
- Cost: S3 is 5x cheaper than HDFS.
- Elasticity: S3 supports elasticity and pay-as-you-go pricing model, HDFS does not.
- SLA (Availability and Durability): S3’s availability and durability is far superior to HDFS’.
- Data locality: On a per node basis, HDFS can yield 6x higher read throughput than S3.
- Performance per Dollar: Given that the S3 is 10x cheaper than HDFS, S3 is almost 2x better compared to HDFS on performance per dollar.
- Compute: Separation of cloud storage and compute allows for new Spark applications.
- HDFS vs. Cloud Storage: Pros, cons and migration tips
- Top 5 Reasons for Choosing S3 over HDFS
Components
- HDFS has a master/slave architecture.
- Clients contact NameNode for file metadata or file modifications and perform actual file I/O directly with the DataNodes.
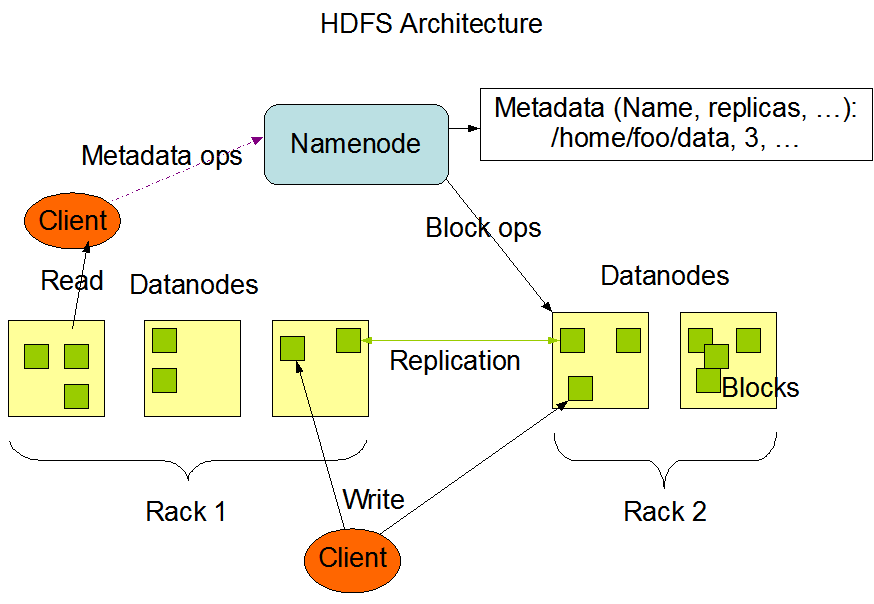
- NameNode:
- A master server that manages the file system namespace and regulates access to files by clients.
- Also determines the mapping of blocks to DataNodes.
- User data never flows through the NameNode.
- Usually a dedicated machine that runs only the NameNode software.
- High availability mode: two separate machines are configured as NameNodes (Active/Standby), edit log file stored in the shared directory, ZooKeeper tracks active NameNode, uses extreme measures to ensure that only one NameNode is used at a time (can cut the power physically)
- DataNodes:
- Manage storage attached to the nodes that they run on.
- Perform block creation, deletion, and replication upon instruction from the NameNode.
- Also responsible for serving read and write requests from clients.
- Usually one per node.
- Example of replication pipeline:
- When a client is writing data to an HDFS file, its data is first written to a local cache. When the local file accumulates a full block of user data, the client retrieves a list of DataNodes from the NameNode. The client then flushes the data block to the first DataNode. The first DataNode starts receiving the data in small portions (4 KB), writes each portion to its local repository and transfers that portion to the second DataNode in the list. And so on.