Deployment to Cloud
- Cloud services like Amazon’s SageMaker can be used for all parts of the ML workflow.
- Cloud services like Google’s Cloud ML Engine are meant to be used primarily for modeling and deployment.
- Machine Learning with Amazon SageMaker
- Machine learning workflow
- What is Azure Machine Learning service?
Amazon SageMaker

- Amazon SageMaker is a fully-managed, end-to-end machine learning service.
- Compared to plug-and-play API services, SageMaker is a platform tailor-made for ML workflows.
- Covers the entire ML workflow to label and prepare data, choose an algorithm, train the model, tune and optimize it for deployment, make predictions, and take action.
- Habitual environment:
- Offers Python and Jupyter notebook environments.
- Provides common ML algorithms, along with other tools, to simplify and accelerate the ML workflow.
- Provides out-of-the-box solution for quick model training.
- Allows using custom algorithms.
- Provides a range of algorithms that can be subscribed to from AWS Marketplace.
- Provides Apache Spark for data pre-processing.
- Allows packaging any ML algorithm into a Docker container and plug it in.
- Amazon SageMaker Examples
- “Zero-configuration” workflow for training:
- No special configuration is required to start training some model remotely in the cloud.
- One can choose from a single general-purpose instance to a distributed cluster of GPU instances.
- Out-of-the-box support for multi-node training.
- Straightforward deployment of trained models to production.
- A developer can track and trigger alarms for changes in performance via Amazon CloudWatch.
- SageMaker is a valuable skill to learn:
- Teaches the best practices in the world of machine learning.
- Guides through the machine learning lifecycle.
- Has a repository with use cases updated continuously.
APIs
- High level functionality:
- Certain choices have been made on the user's behalf.
- Makes development much quicker.
- Low level functionality:
- Requires knowing each of the objects involved in the SageMaker environment.
- Benefits from allowing the user a great deal of flexibility.
- Python SDK Documentation
- Developer Documentation
- Search for code definitions in Python SDK Code
Workflow
Create an Amazon S3 bucket
- Amazon S3 is used as a central storage service when using SageMaker.
- Data (also results, checkpoints, logs, etc.) must then be stored in S3 object storage.
- Create a dedicated S3 bucket for a single project.
- There is no practical limit to the size of the data set.
- But it takes around 20 minutes to download 100Gb worth of images to a training instance.
- Thus, do all the preliminary trials and polish the model elsewhere.
- S3 bucket must be in the same region as the training job.
- One can create a default bucket with
sess.default_bucket()
Create a notebook instance
- Notebook Instances provide a convenient place to process and explore data in addition to making it very easy to interact with the rest of SageMaker's features.
- The notebook instances are fully-managed - they are not listed in the console.
- Pro tips:
- Pick the right family, size and version of the EC2 instance.
- Pick the right EBS volume (a bit more than the training data, folder
~/SageMaker) - Add or create a git repository for collaboration.
- Configure security settings (encryption, internet access)
- Use a lifecycle config (running a bash script every time you start, also in background)
- Elastic inference: Optionally attach a portion of a GPU for local inference.
- Use lambda for stopping, resize on the fly, and use multiprocessing
- Fully-Managed Notebook Instances
Build the dataset
- Having large amounts of training data could be a differentiator in building high-quality models.
- Use Amazon SageMaker Ground Truth to create a labeled dataset.
- Uses a combination of human labelers and an active learning model to label data.
- Human labelers:
- Workers from Amazon Mechanical Turk, a vendor company, or an internal, private workforce.
- Bounding boxes, image and text classification, semantic segmentation, named entity recognition.
- Active learning model:
- An ML algorithm decides which data needs to be labeled by humans.
- Labels data points and sends those with a confidence below a threshold to human workers.
- Reduces the time and cost to label datasets by about 70%.
- Increase the quality by increasing the number of labelers per dataset object.
- Use majority voting or probabilities of labelers being correct by looking at their past work.
- Build Highly Accurate Training Datasets at Reduced Costs
Explore and transform the data
- Explore training data to determine what to clean up and which transformations to apply.
- Split the training dataset into training and validation.
# Example: Split into train, validation and test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.33)
X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X_train, y_train, test_size=0.33)
- Save the datasets into files and upload them to S3.
- Do the same with test to use SageMaker's Batch Transform functionality to test the model.
- The datasets should contain no headers or index, the label should occur as first column.
- Also upload all artifacts that are required by inference code (e.g. word vocabulary)
# Example: Upload training data to S3
pd.concat([y_train, X_train], axis=1).to_csv(os.path.join(data_dir, 'train.csv'), header=False, index=False)
train_location = session.upload_data(os.path.join(data_dir, 'train.csv'), key_prefix=prefix)
- One can transform them into
RecordSetformat to do this automatically.
# Example: Create training RecordSet
X_train_np = X_train.astype('float32')
y_train_np = y_train.astype('float32')
formatted_train_data = learner.record_set(X_train_np, labels=y_train_np)
- Think of ETL as a software application.
- Wrap steps into modular, readable, reusable functions.
- Inference pipelines:
- Deploy up to 5 containers as a pipeline model (
PipelineModel) - For example, pre-process -> PCA -> XGBoost -> post-process.
- They will run in serial and co-located on the same EC2 instance.
- This is one way to productionize the ETL code.
- Deploy up to 5 containers as a pipeline model (
Build the model
- Models are essentially a combination of model artifacts formed during a training job (such as weights) and an associated Docker container (code) that is used to perform inference.
- SageMaker uses managed Docker containers when running scripts, training algorithms or deploying models.
- Hosted on Amazon ECR, versioned, and can be modified and extended easily.
- Enable endpoints, batch transform, and inference pipelines by design.
- Can be developed and run locally for testing.
- Built-in Machine Learning Algorithms
# Example: Built-in estimator
container = get_image_uri(session.boto_region_name, 'xgboost')
xgb = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(session.default_bucket(), prefix),
sagemaker_session=session)
- Bring own script, algorithm or model:
- Script mode: Quick training but limited options.
- Custom container: Most flexible but more time consuming to develop.
- Marketplace: Easy to add value quickly but less insight into solution.
- Bring Your Own Custom ML Models
- Use the Deep Learning Framework of Your Choice
# Example: Custom sklearn estimator
from sagemaker.sklearn.estimator import SKLearn
sklearn_estimator = SKLearn(entry_point='train.py',
source_dir='source_sklearn',
role=role,
train_instance_count=1,
train_instance_type='ml.c5.xlarge',
sagemaker_session=sagemaker_session,
hyperparameters={},
output_path='s3://{}/{}/output'.format(bucket, prefix))
Train and evaluate the model
- Before starting a training job, ensure that the model behaves correctly (locally, on a subset of data)
- Training Jobs allow us to create model artifacts by fitting various machine learning models to data.
- SageMaker spins up one or several “training instances”, copies all the necessary scripts and data from S3 there, runs the training, and uploads the model back to S3.
- Every model run on a training job has its own ephemeral (short-lived) EC2 cluster.
- No more virtual environments, conflicting package installations, and resource dependencies.
- The cluster comes down immediately after the model finished training.
- The logs are sent to CloudWatch and can be monitored via console or notification system.
- A training job requires input and output S3 locations, Docker container location, and EC2 configuration.
# Example: Fit the estimator
s3_input_train = sagemaker.s3_input(s3_data=train_location, content_type='csv')
s3_input_validation = sagemaker.s3_input(s3_data=val_location, content_type='csv')
xgb.fit({'train': s3_input_train, 'validation': s3_input_validation})
- Distributed training:
- Horovod enables running multiple processes per node (multi-GPU training)
- Use production-ready, infinitely scalable algorithms that support data streaming.
- Use incremental training (resume a previous training job) to save both time and resources.
- Scale up Training of Your ML Models with Distributed Training
- Pro tips:
- Read white papers, always put label into the 1st column, and tune hyperparameters.
- Use examples provided by Amazon, pipe mode for streaming data from S3, and incremental training.
- Use SageMaker Search to compare results of previous jobs.
- Run training jobs in parallel from the notebook.
- Soft limit the number of EC2 instances used for training job.
- Do local sanity checks before starting a training job.
- Train Your ML Models Accurately
Tune hyperparameters
- Hyperparameter Tuning allows us to create multiple training jobs each with different hyperparameters in order to find the hyperparameters that work best for a given problem.
- SageMaker provides an automated way of doing hyperparameter tuning.
- One tuning job is just an umbrella over multiple training jobs.
- One can specify the maximum number of training jobs and parallel training jobs.
- SageMaker then provides the name of the best-performing job based on the objective metric.
# Example: Hyperparameter tuning
from sagemaker.tuner import IntegerParameter, ContinuousParameter, HyperparameterTuner
# Make sure to set any model specific hyperparameters that we wish to have default values
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
objective='reg:linear',
early_stopping_rounds=10,
num_round=200)
# Create the hyperparameter tuner
xgb_tuner = HyperparameterTuner(estimator=xgb,
objective_metric_name='validation:rmse',
objective_type='Minimize',
max_jobs=20,
max_parallel_jobs=3,
hyperparameter_ranges={
'max_depth': IntegerParameter(3, 12),
'eta': ContinuousParameter(0.05, 0.5),
'min_child_weight': IntegerParameter(2, 8),
'subsample': ContinuousParameter(0.5, 0.9),
'gamma': ContinuousParameter(0, 10),
})
- Each notebook is self contained, that is, models cannot be shared between them.
- But one can use
attachmethod to create an Estimator object which is attached to an already completed training job (only the name of the job required)
- But one can use
xgb_attached = sagemaker.estimator.Estimator.attach(xgb_tuner.best_training_job())
- CloudWatch provides a UI through which we can examine various logs generated during training.
- This can be especially useful when diagnosing errors.
- Pro tips:
- Use Bayesian optimization for efficiency, or random search for full parallelism.
- Use warm start: take the previous evaluations as a starting point (reduces the search space)
- Use transfer learning: permits changing the search space, algorithm image or dataset.
- Check docs on which hyperparameters are valid for tuning.
- Tune Your ML Models to the Highest Accuracy
Test the model
- Use SageMaker's Batch Transform functionality to perform inference on a large dataset.
- SageMaker initializes compute instances and distributes the workload between them.
- Enables running inference without a need of a persistent endpoint.
# Example: Batch transform on test set
xgb_transformer = xgb_attached.transformer(instance_count=1, instance_type='ml.m4.xlarge')
xgb_transformer.transform(test_location, content_type='text/csv', split_type='Line')
xgb_transformer.wait()
!aws s3 cp --recursive $xgb_transformer.output_path $data_dir
test_pred = pd.read_csv(os.path.join(data_dir, 'test.csv.out'), header=None)
Deploy the model
- Deploy the trained model to a production-ready cluster.
- Integrate endpoints into internet-facing applications.
- Monitor the inferences, collect "ground truth," and evaluate the model to identify drift.
- Scale and manage the production environment.
# Example: Deploy the model
xgb_predictor = xgb.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
- To get inferences for an entire dataset, use Amazon SageMaker batch transform.
- Enables preprocessing of and getting inferences from large datasets.
- Enables serving predictions on a schedule (event trigger -> Lambda -> S3 -> SageMaker)
- Similar to an endpoint, operates with RESTful API.
- To get one inference at a time in real time, set up a persistent endpoint.
- Allows to perform inference on small amounts of data by sending it bit by bit.
# Example: Predict on test set using endpoint
def predict(data, rows=512):
# We split the data into chunks and send each chunk seperately, accumulating the results.
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = np.array([])
for array in split_array:
predictions = np.append(predictions, predictor.predict(array))
return predictions
predictions = predict(X_test.values)
- Endpoints are the actual HTTP URLs that are created by SageMaker.
- SageMaker launches a compute instance running a Docker container with the inference code and a URL that data can be sent to and returned from.
- So, if you are no longer using a deployed endpoint, shut it down.
- Endpoint Configurations act as blueprints for endpoints:
- What resources should be used?
- What models should be used?
- How the incoming data should be split up among deployed models?
- Pro tips on endpoints:
- Endpoints require serializing - converting the data into something that can be transferred using HTTP. The backend also needs to know how to deserialize the data.
- Only entities that are authenticated with AWS can send or receive data from the deployed model. Thus, use an API Gateway to create HTTP endpoints (URL addresses) that are integrated with AWS services and open to the public (charged per execution)
- Use Lambda function for pre and post processing, e.g., tokenization (charged per execution)
# Example: Creating a Lambda function
import boto3
def lambda_handler(event, context):
runtime = boto3.Session().client('sagemaker-runtime')
response = runtime.invoke_endpoint(EndpointName = '**ENDPOINT NAME HERE**',
ContentType = 'text/plain',
Body = event['body'])
result = response['Body'].read().decode('utf-8')
return {
'statusCode' : 200,
'headers' : { 'Content-Type' : 'text/plain', 'Access-Control-Allow-Origin' : '*' },
'body' : result
}
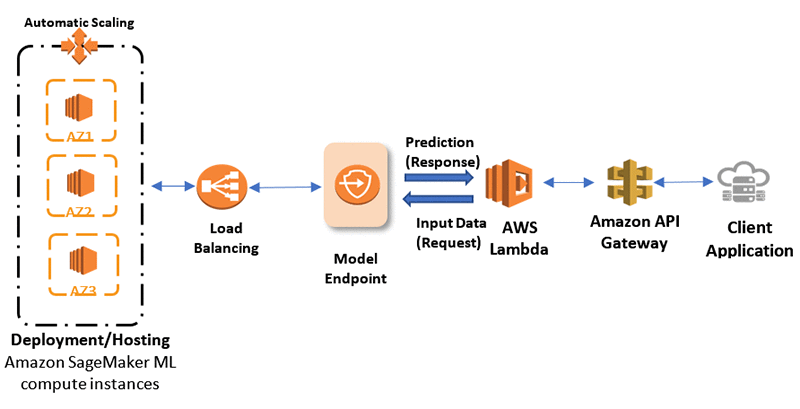
- Common deployment workflow:
- The user does an action.
- The website sends the user data off to an HTTP endpoint, created using API Gateway.
- The endpoint acts as an interface to a Lambda function.
- The Lambda function processes the data and sends it off to the endpoint using Boto3.
- The model performs inference on the data and returns the results to the Lambda function.
- The Lambda function returns the results to the original caller using the HTTP endpoint.
- Lastly, the website receives the inference results and displays those results to the user.
- Pro tips:
- Turn endpoints off when not in use with Lambda.
- Use inference pipelines for pre and post processing.
- Bring multiple models in a single Docker container.
- Consider the size of the data hitting a single endpoint (batch transform?)
- One can train the model elsewhere and just host it using SageMaker.
- Use streaming for faster training, faster inference and smaller payload size.
- Keep the payload small, cache the results in a database.
- Deploy Your ML Models to Production at Scale
Update the model
- One may be confronted with a new data distribution that is hitting the model.
- For example, for NLP, the frequency of use of different words could have changed: Maybe there is some new slang that has been introduced or some other artifact of popular culture that has changed the way that people write.
- Once accumulated enough user data, perform data labeling to build the new test dataset.
- Health-checking: Validate the model to ensure that it satisfies constraints and is still effective.
- Such constraints may include accurate predictions, interpretability and costs.
- Use batch transform to test the model on the new dataset.
- Re-train the model:
- Make sure that the new model also performs well on the original data.
- Model comparison:
- Create an endpoint that sends data to multiple models for an A/B test (using routing)
- Use a low-level approach to construct an endpoint configuration.
- Do not assume that different models will return data in the same way (JSON or CSV?)
# Example: Deploy a combined endpoint
# Create endpoint configuration
combined_endpoint_config_name = "boston-combined-endpoint-config-" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
combined_endpoint_config_info = session.sagemaker_client.create_endpoint_config(
EndpointConfigName=combined_endpoint_config_name,
ProductionVariants=[
{
"InstanceType": "ml.m4.xlarge",
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": linear_model_name,
"VariantName": "Linear-Model"
}, {
"InstanceType": "ml.m4.xlarge",
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": xgb_model_name,
"VariantName": "XGB-Model"
}])
# Create endpoint
endpoint_name = "boston-update-endpoint-" + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
endpoint_info = session.sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=combined_endpoint_config_name)
endpoint_dec = session.wait_for_endpoint(endpoint_name)
- Ask SageMaker to update the existing endpoint so that it uses the new configuration.
- SageMaker first deploys the new model and then shuts down the old one (= no downtime)
# Example: Update the endpoint
session.sagemaker_client.update_endpoint(EndpointName=endpoint_name, EndpointConfigName=linear_endpoint_config_name)
endpoint_dec = session.wait_for_endpoint(endpoint_name)