Speech Recognition
- The deep acoustic model extracts higher-level representations of speech features and computes the probability that in that particular frame, a phoneme is pronounced.
- There are 2 main types of deep neural networks used for speech recognition:
- Recurrent acoustic model: the system sequentially sees one vector after the other. When processing a vector, it will not only use information that it sees in the features but it will also use the information from the previous prediction. For instance, it will take into account the fact that the probability that there is a vowel after a consonant is higher than having a consonant again because that’s usually how words are built.
- Convolutional acoustic model: it’s the same type of neural network as the one used in computer vision. It will look at speech features as if we were looking at an image and it is going to use some context around the speech features to compute probabilities.
- Have you ever wondered how Amazon Echo, Siri or Google Home work?
- How to do Speech Recognition with Deep Learning
- Combining CNN and RNN for spoken language identification
Challenges
- The big problem is that speech varies in speed:
- Automatically aligning audio files of various lengths to a fixed-length piece of text turns out to be hard.
- Accented speech and noisy speech (with heavy environmental noise) are still very challenging.
- Languages without standard orthography such as Moroccan Arab are problematic since two different people won’t write a sentence in the same way because there is no standard way to write words.
- Language evolution is a problem since new words and accents continuously appear in the language and the speech recognition system needs to be retrained to incorporate these evolutions.
- Unlike humans, lots of data are needed to train a speech recognition system.
Feature extraction
- The role of feature extraction is to transform the signal into a representation of the acoustic signals that will be relevant for machine learning.
- This is in fact done to try to reproduce the human ear perception.
- But it turns out that the human ear is more sensitive to variations in low frequencies than in high frequencies (Mel-filterbanks logarithmic scale can be applied here).
- Using a spectrogram and optionally a 1D conv layer is a common pre-processing step prior to passing audio data to an RNN, GRU or LSTM.
Digital sampling
- According to the Nyquist theorem, we can use math to perfectly reconstruct the original sound wave from the spaced-out samples - as long as we sample at least twice as fast as the highest frequency we want to record.
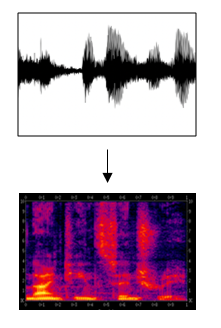
Spectrogram
- Trying to recognize speech patterns by processing raw samples directly is difficult:
- There are some low sounds, mid-range sounds, and high-pitched sounds sprinkled in. For example, a piano music is as a combination of musical notes mixed together into one complex sound.
- Also, even human ear doesn't process raw wave forms, but different frequencies.
- The standard practice is to first extract spectrograms or MFCC (Mel-Frequency Cepstral Coefficients) out of the raw audio.
- A spectrogram is a visual representation of sound with a time and a frequency axis and pixel intensities representing the amplitude or energy of the sound at that moment and at that frequency.
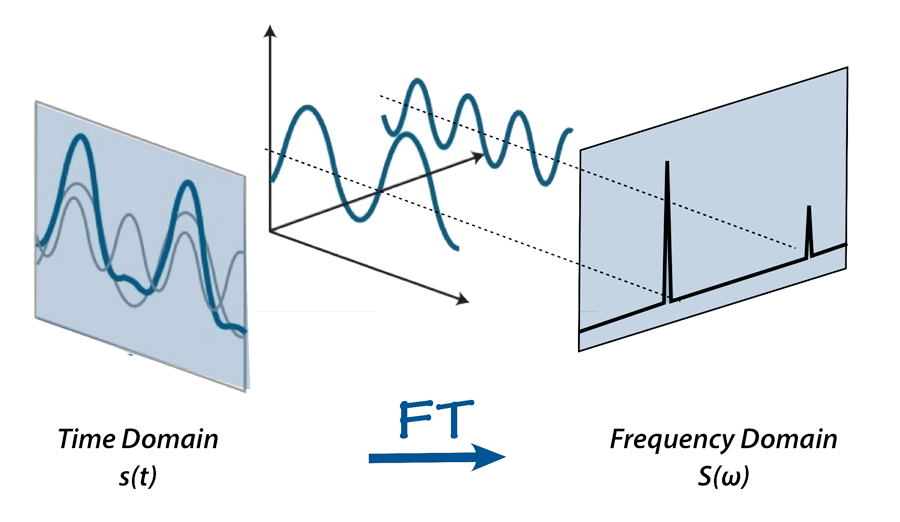
- A spectrogram is computed by sliding a window over the raw audio signal, and calculates the most active frequencies in each window using a Fourier transformation.
- Short Time Fourier Transform decomposes a function of time (a signal) into the frequencies that make it up, in a way similar to how a musical chord can be expressed as the frequencies (or pitches) of its constituent notes.
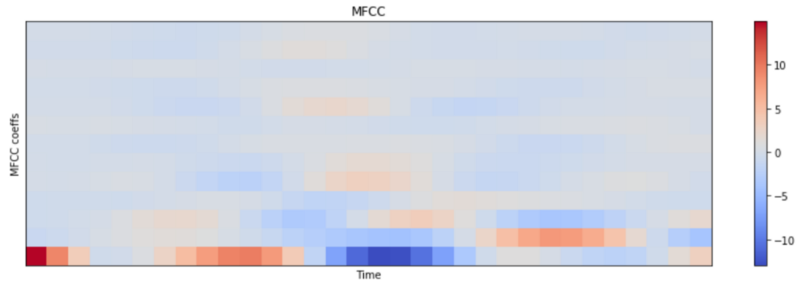
- MFCCs are yet another transformation on spectrograms and are meant to capture characteristics of human speech better.
- There are also delta and delta-delta transformations on top of MFCC, which you probably can think of them as first and second derivatives.
- MFCCs are the standard feature representation in popular speech recognition frameworks.
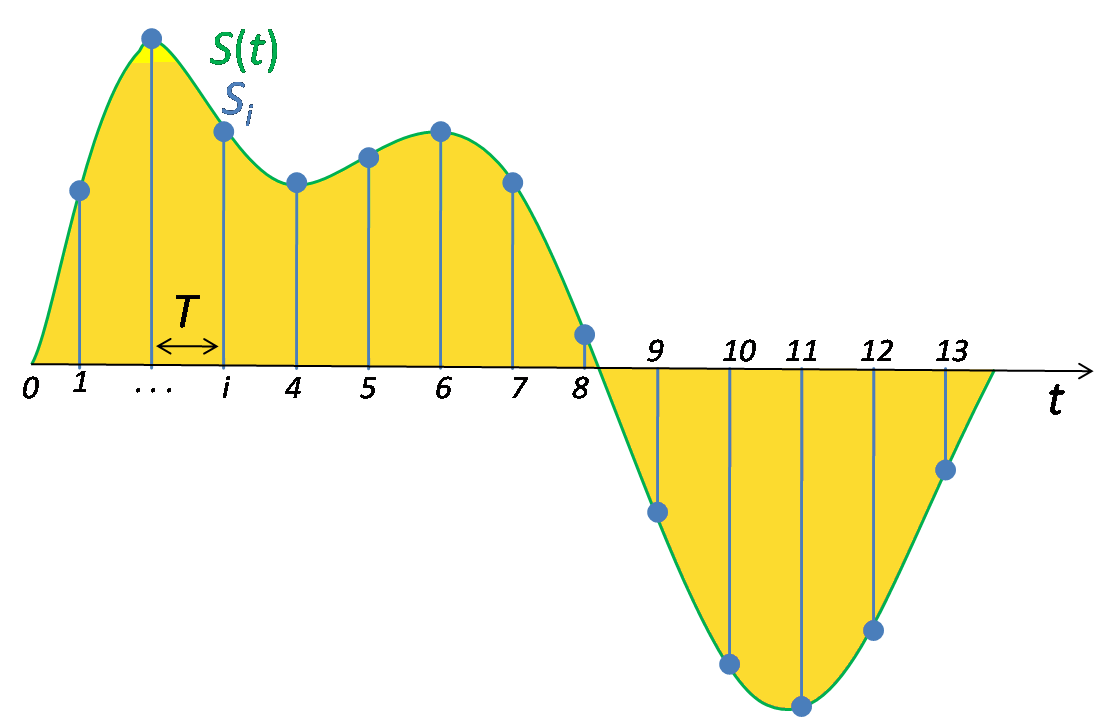
- We need to slice the spectrogram into short-time segments (typically 10 milliseconds) shifted with a fixed timestep.
Data synthesis
- Data synthesis is an effective way to create a large training set for speech problems.
- The training data can be generated using the audio clips of activates, negatives, and backgrounds.
- Mix background noises with word files to get some different ‘environments’ for your sounds to live in during training.
- Apply feature engineering to create more “unknown” samples (negatives):
- You can for example cut and paste pieces of words together to create new words, or you can use pitch shifting or reversing the samples.
CTC
- Without Connectionist Temporal Classification (CTC), every character of a transcription has to be aligned to its exact location in the audio file:
- The small fixed-length analysis frames used in the acoustic model do not necessarily correspond to a single sound, because a sound might occupy several frames. Also, it is very expensive to correctly label each vector with the correct phoneme because it needs human manual annotation done by professionals.
- CTC is a loss function useful for performing supervised learning on sequence data, without needing an alignment between input data and labels.
- Basically, instead of maximizing the probability of one particular phoneme, it will compute each path’s probability and maximize the valid paths to give us the phonetic transcription of the word.
- It will consider the outputs from the acoustic model as a graph and take each probability of a phoneme as a node. Each path will have its own probability, which will simply be the product of the probability of the nodes.
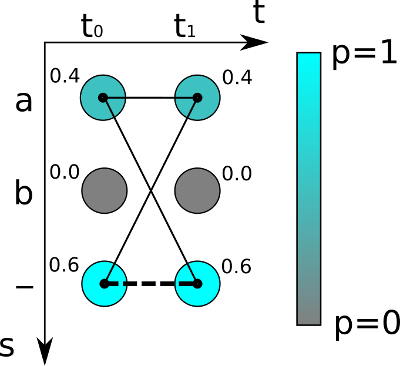
- CTC computes the probability of an output sequence as a sum over all possible alignments of input sequences that could map to the output sequence.
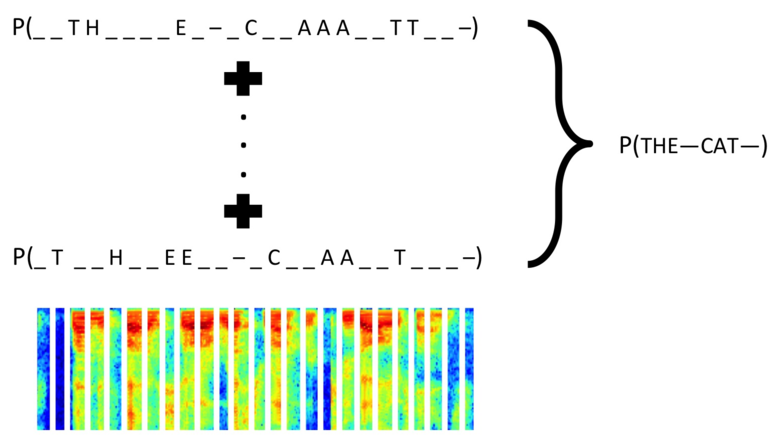
- Computing the sum of all such probabilities explicitly would be prohibitively costly due to the combinatorics involved, but CTC uses dynamic programming to dramatically reduce the complexity of the computation.
- In order to encode duplicate characters, CTC introduces a pseudo-character called blank.
- Sequence Modeling With CTC
- An Intuitive Explanation of Connectionist Temporal Classification