Attention Mechanisms
- At any given moment, our minds concentrate on a subset of the total information available to them. This is important, because the field of sensation is wide, and the mind’s bandwidth to process information is narrow, and some inputs are indeed more important that others, with regard to any given goal.

- Neural networks can achieve this same behavior using an attention mechanism:
- It distributes attention over several inputs or encoded hidden states.
- And just as importantly, it accords different weights, or degrees of importance, to those inputs which are highly correlated with the current output.
- To make attention differentiable, the network has to focus on each input, just to different extents.
- In neural networks, attention is a memory-access mechanism, where memory is an abstract layer defining the context for each incoming time step.
- Attention mechanisms are components of memory networks, which focus their attention on external memory storage.
- Attention is used for machine translation, speech recognition, reasoning, image captioning, summarization, and the visual identification of objects.
- Attention? Attention!
- How Does Attention Work in Encoder-Decoder Recurrent Neural Networks
- Attention and Augmented Recurrent Neural Networks
- Implementing NLP Attention Mechanisms with DeepLearning4J
Attention model
Encoder-decoder approach
- The encoder memorizes a long sequence into one vector, and the decoder has to process this vector to generate the translation.
- A potential issue with a traditional encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector (also known as sentence embedding, “thought” vector).
- By utilizing the attention mechanism, it is possible for decoder to capture global information rather than solely to infer based on one hidden state.
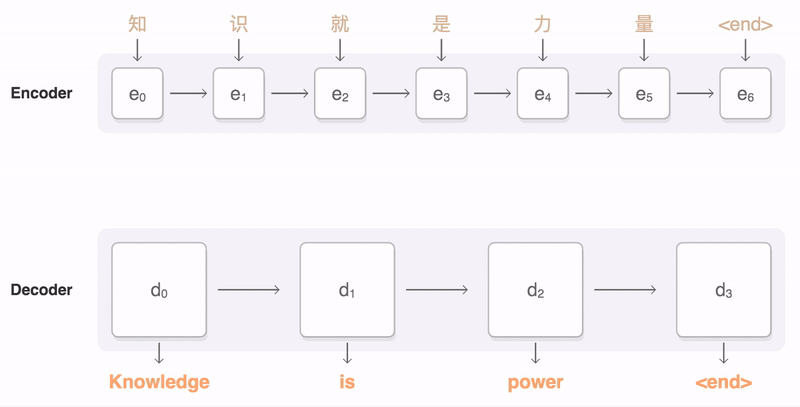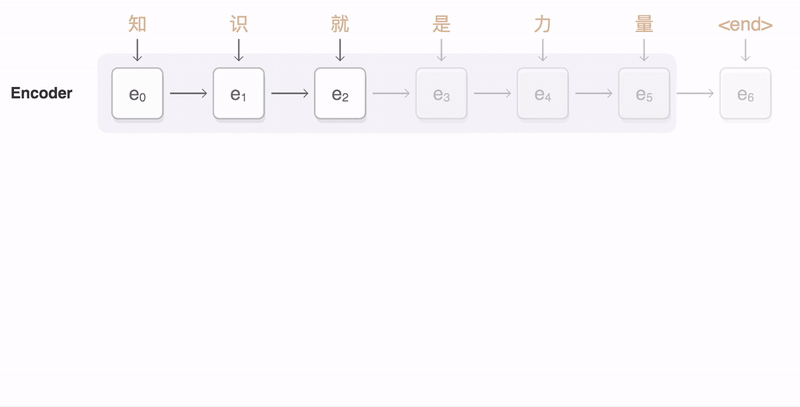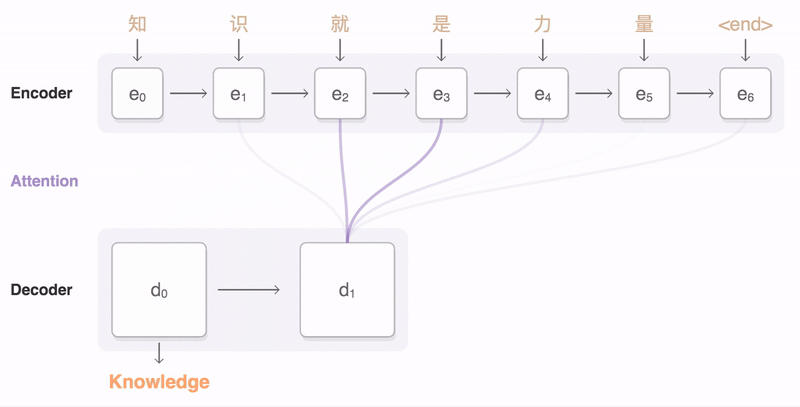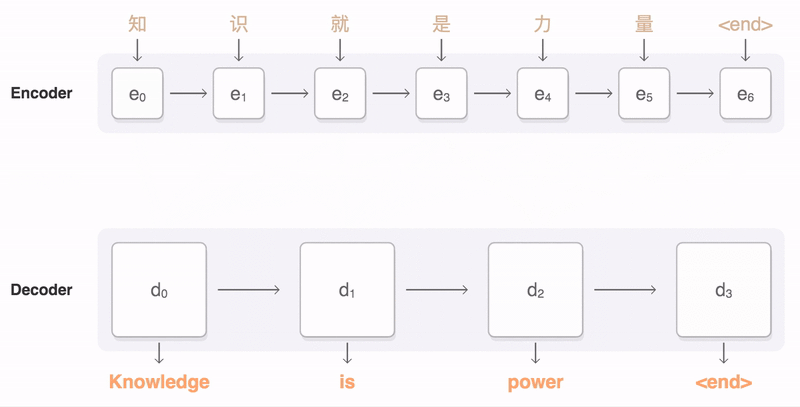
- The encoder is a bidirectional RNN with forward and backward hidden states combined into one vector.
- The decoder is a RNN with a forward hidden state for the output word at some position.
- This hidden state is calculated based on the previous state and the context vector.
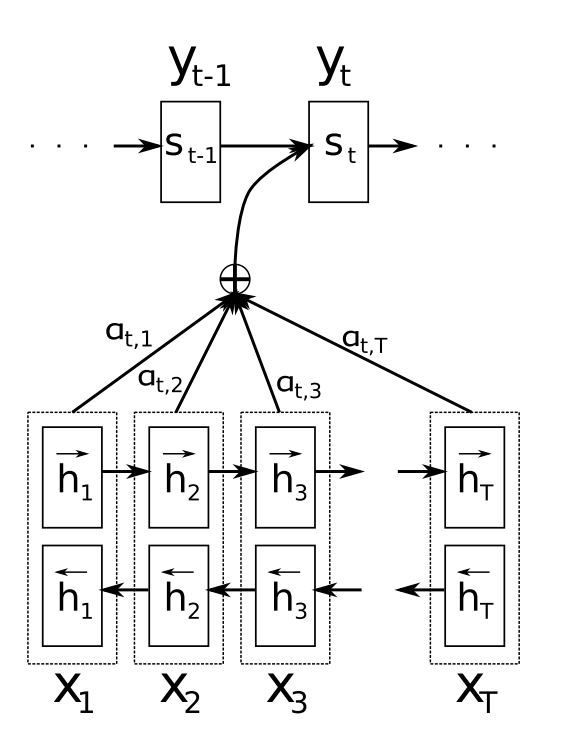
The context vector is a sum of hidden states (also called annotations) of the input sequence, weighted by alignment scores, which define how much of each hidden state in encoder should be considered for each output in decoder.
The alignment scores \(\alpha\) are calculated for each pair \(i\) of the encoded input \(h_i\) and the previous output of the decoder \(s_{t-1}\), based on how well they match.
- This is done by a feedforward NN that is trained with all the other components of the system. $$\large{e_{ti}=a(s_{t-1},h_i)}$$
- The alignment scores are then normalized using a softmax function. $$\large{\alpha_{ti}=\frac{\text{exp}(e_{ti})}{\sum_{j=1}{\text{exp}(e_{tj})}}}$$
- So \(\alpha_{ti}\) is the amount of attention \(y_t\) should pay to \(x_i\).
- Sum over the attention weights for each element in the input sequence should be 1.
The matrix of alignment scores is a nice byproduct to explicitly show the correlation between source and target words.

- Finally, the context vector becomes a weighted sum of the annotations (hidden states) \(h\) and normalized alignment scores \(\alpha\).
$$\large{c_t=\sum_{i=1}{\alpha_{ti}h_i}}$$
- Each decoder output now depends not just on the last decoder state, but on a weighted combination of all the input states. While the context vector has access to the entire input sequence, we don’t need to worry about forgetting.
Pros
- Attention overcomes the information bottleneck in CNNs and RNNs by accessing the whole input.
- Attention weights help us visualize what the model deems important.
- We can render attention as a heat map over input data such as words and pixels, and thus communicate to human operators how a neural network made a decision.
Cons
- That advance, like many increases in accuracy, comes at the cost of increased computational demands.
Transformer
- TODO
BERT
- TODO