Neural Machine Translation
- Neural machine translation (NMT) is the use of neural network models to learn a statistical model for machine translation.
- The strength of NMT lies in its ability to learn directly, in an end-to-end fashion, the mapping from input text to associated output text.
- One of the most reliable ways is the use of recurrent neural networks organized into an encoder-decoder architecture that allow for variable length input and output sequences.
Encoder-decoder model
- Encoder:
- Reads the input sequence and encoding it into a fixed-length vector (which is a lower-dimensional representation, or information bottleneck).
- Decoder:
- Decodes the vector and outputting the reconstructed/translated sequence.
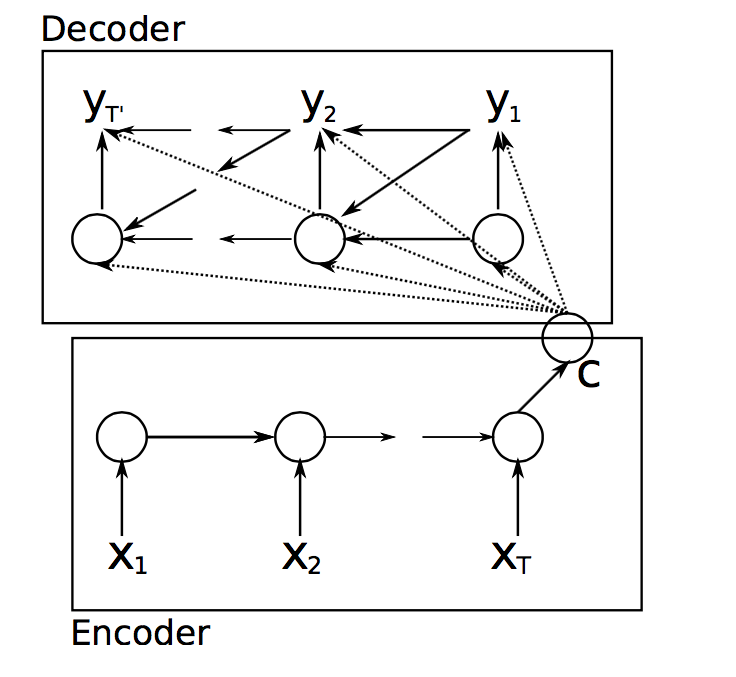
- The encoders are trained with the decoders:
- The loss function is based on the delta between the actual and reconstructed/translated input.
- The optimizer will train both encoder and decoder to lower the reconstruction/translation loss.
Sequence generation
- The sequence of data contains crucial information about what is coming next.

- Machine translation model can be thought of as a “Conditional Language Model”, for a system that translates French to English, the model can be thought of probability of English sentence conditioned on French sentence.
- Sequence models often operate by generating probability distributions across the vocabulary of output words and it is up to decoding algorithms to sample the probability distributions to generate the most likely sequences of words.
- Each of the conditional distributions will be predicted using the output unit at a given time step.
- We can then use the chain rule of conditional probability to calculate the joint probability of the sequence.
$$\large{P(w_1w_2...w_n)=\prod_{i}{P(w_i|w_1w_2...w_{i-1})}}$$ $$P(\text{water is clear})=$$ $$P(\text{water})\times P(\text{is}|\text{water})\times P(\text{clear}|\text{water is})$$
- This way an ancestral sampling can be achieved:
- pick the first character/word, called the seed, to start the sequence,
- create a probability distribution over all possible outputs (using softmax),
- then randomly sample from that distribution,
- and finally feed the sampled character/word back in as an input in the next time step.
Greedy search
- Decoding the most likely output sequence involves searching through all the possible output sequences based on their likelihood.
- The search problem is exponential in the length of the output sequence and is intractable (NP-complete) to search completely.
- Use approximations to find a solution efficiently:
- A simple approximation is to use a greedy search that selects the most likely word at each step in the output sequence.
- While this approach is often effective, it is obviously non-optimal.
Beam search
- The beam search generates the sequence word by word while keeping a fixed number (beam) of active candidate sequences at each time step.
- At each step, the probability distributions of \(k\) candidates are generated. If any one maximizes the joint probability, the algorithm halts. Otherwise, it selects the \(k\) best successors from the complete list and repeats.
| Light beam | Beam search strategy |
|---|---|
 | 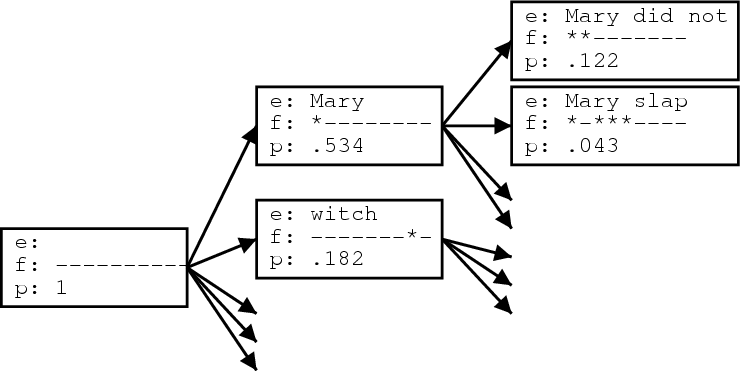 |
- Unlike exact search algorithms like BFS (Breadth First Search) or DFS (Depth First Search), Beam Search runs faster but is not guaranteed to find the exact solution.
- By increasing the beam size, the translation performance can increase at the expense of significantly reducing the decoder speed.
- Common beam width values are \(k=1\) for a greedy search and values of \(k=5\) or \(k=10\) for common benchmark problems in machine translation.
- Beam search
- Seq2Seq with Attention and Beam Search
Length normalization
- Multiplying conditional probabilities may cause a numerical underflow.
- In practice, we are summing their logarithms.
- The other problem is the preference of smaller sequences over the longer ones:
- Because multiplying more fractions gives a smaller value, returning fewer fractions yields a better result. Here we divide the sum by the number of elements in the sequence powered by the length normalization coefficient \(\alpha\). In practice, \(\alpha=0.7\) is somewhere in between two extremes.
Evaluation
- Human judgment is the benchmark for assessing automatic metrics, as humans are the end-users of any translation output.
- Therefore, any metric must assign quality scores so they correlate with human judgment of quality.
- But even if a metric correlates well with human judgment in one study on one corpus, this successful correlation may not carry over to another corpus.
BLEU score
- BLEU uses a modified form of precision to compare a candidate translation against multiple reference translations.
- For each word in the candidate translation, the algorithm takes its maximum total count, in any of the reference translations.
- Since, however, using individual words as the unit of comparison is not optimal, BLEU computes the same modified precision metric using n-grams.
- It turns out that if a machine outputs a small number of words it will get a better score, so that a brevity penalty is introduced.
- It has been shown that BLEU scores correlate well with human judgment of translation quality.
- More (and more diverse) reference translations result in more accurate scores.
- Evaluating models