Wide Column Stores
- Google's BigTable is considered to be the origin of this class of databases.

- Wide column stores use tables, rows, and columns.
- Seem to store data in rows, but actually serialize the data into columns.
- The names and format of the columns can vary from row to row.
- Basically a hybrid between a key-value store and RDBMS.
- They can be seen as two-dimensional key-value stores.
- Should not be confused with the column-oriented storage.
- Cassandra is column family but not column-oriented (when column is stored separately on disk).
- Hbase is column family as well as stores column families in column-oriented fashion.
- Often support the notion of column families (similar to RDBMS tables)
- This allows storing somewhat related data together.
- Column stores handle wide, sparse tables very well (since NULLs are not stored)
Apache HBase
- Apache HBase is an open-source, distributed, versioned, column-oriented database.
- Modeled after Google's Bigtable: A Distributed Storage System for Structured Data
- Designed to provide random access to high volume of structured or unstructured data.
- Sits on top of HDFS:
- Achieves fast lookups on HDFS
- Leverages the fault tolerance feature of HDFS
- But has a single point of failure
- Main features:
- Linear and modular scalability
- Strictly consistent reads and writes (CP)
- Automatic and configurable sharding of tables
- Automatic failover support between RegionServers
- Easy to use Java API for client access
- Block cache and Bloom Filters (whether an element is present in a set) for real-time queries
- Very fast way to expose results of Spark to other systems
- Has made strong consistency of reads and writes a core design tenet:
- All accesses are seen by all parallel processes in the same order, sequentially.
- Only one consistent state can be observed, as opposed to weak consistency.
- There is no query language, just CRUD APIs.
- HBase: The Definitive Guide by Lars George
Compared to HDFS
- HDFS is optimized for batch processing and streaming in a sequential manner.
- The entire dataset must be searched even for the simplest of jobs.
- HBase can access any point of data in a single unit of time.
- HDFS follows write-once read-many ideology.
- HBase allows for real-time changes and random reads and writes.
- HBase:
- Stores key/value pairs in columnar fashion.
- Provides low latency access to small amounts of data.
- Provides flexible data model.
Compared to Apache Accumulo
- Apache Accumulo is a highly scalable sorted, distributed key-value store based on Google's Bigtable.
- Another BigTable clone like HBase.
- Built on top of Apache Hadoop, Apache ZooKeeper, and Apache Thrift.
- Offers a better security model (cell-based access control)
- Offers server-side programming.
- Consider Accumulo if you have complex security requirements.
Architecture
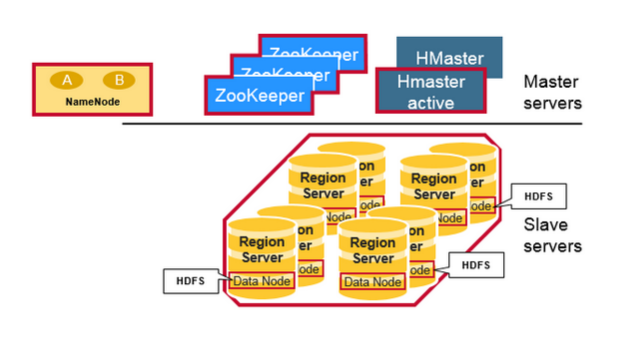
- HBase has a master/slave type of architecture.
- Region servers serve data for reads and writes.
- HBase Master process handles region assignment and DDL (create, delete tables) operations.
- Zookeeper, which is part of HDFS, maintains a live cluster state.
- The HDFS DataNode stores the data that the Region Server is managing.
- Region Servers are collocated with the HDFS DataNodes for data locality.
- A region server can serve about 1,000 regions.
- A region contains all rows in the table between the start and end keys.
- The HDFS NameNode maintains metadata information.
- An In-Depth Look at the HBase Architecture
Write path
- The first step is to write the data to the write-ahead log, the WAL.
- The WAL is used to recover not-yet-persisted data in case a server crashes.
- Updates are appended sequentially.
- The data is then placed in the MemStore.
- The MemStore is the write cache (compared to BlockCache, the read cache)
- Stores new data the same as it would be stored in an HFile.
- There is one MemStore per column family per region.
- Then, the put request acknowledgement returns to the client.
- After a limit, the entire MemStore is flushed to a new HFile in HDFS.
- HFile contains sorted key/values.
- This is a sequential write and thus very fast.
Data modeling
- Similar to Apache Cassandra, you will have to denormalize your schemas.
- The main principle is Denormalization, Duplication, and Intelligent Keys (DDI)
HBase's model
- An HBase table consists of multiple rows.
- Row in HBase consists of a row key (PRIMARY KEY) and one or more columns.
- Row key can be any arbitrary array of bytes.
- Rows are always sorted lexicographically by their row key.
- The goal is to store data in such a way that related rows are near each other.
- For example, if row keys are domains, store them in reverse (
org.apache.www)
- For example, if row keys are domains, store them in reverse (
- Columns in HBase are grouped into column families.
- All columns in a column family are stored together in HFile.
- A column family must be string.
- Each column family has a set of storage properties (compression etc.)
- Column families are fixed at table creation.
- Columns are often referenced as
family:qualifier(for example,content:pdf)- Column qualifiers can be any arbitrary array of bytes.
- Mutable and may differ greatly between rows.
- One could have millions of columns in a particular column family.
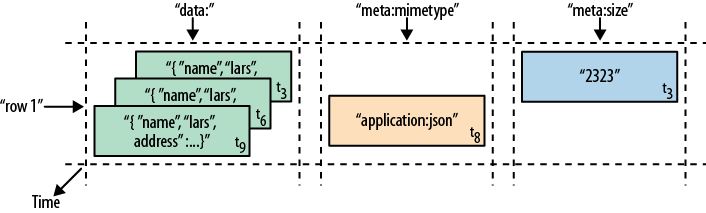
- HBase model is a sparse, distributed, persistent, multidimensional map, which is indexed by row key, column key, and a timestamp.
- Timestamp is the identifier for a given version of a value.
- NULLs are free of any cost: they do not occupy any storage space.
(Table, RowKey, Family, Column, Timestamp) → Value
Apache Cassandra
- NoSQL with a twist
- Cassandra is a peer-to-peer, read/write anywhere architecture.
- No master node
- Any user can connect to any node in any data center.
- Partitions and replicates all writes automatically throughout the cluster.
- Cassandra is designed to handle big data across multiple nodes with no single point of failure.
- Provides scalability and high availability (AP)
- Provides tunable consistency (AP -> CP)
- Good choice for mission-critical data
- Developed by Facebook
- Based on Google Bigtable (2006) and Amazon Dynamo (2007), but open-source.
- Uses architecture of Dynamo and data model of BigTable.
- Cassandra: Daughter of Dynamo and BigTable
- Cassandra is a partitioned row and column-family store.
- Cassandra is schema-full, all the way (= fixed columns)
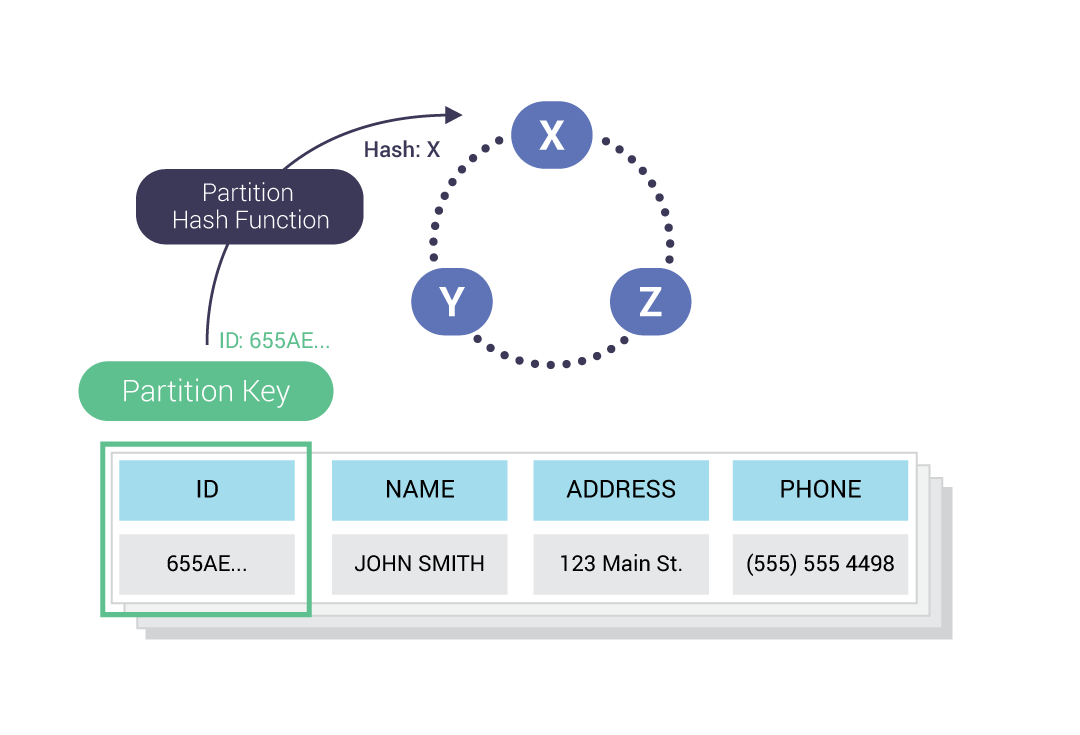
- Rows are organized into tables with a required primary key.
- A hash function is applied on the primary key to (evenly) distribute the data.
- Main features:
- Decentralized load balancing and scalability.
- Data is automatically replicated to multiple nodes for fault-tolerance.
- There are no single points of failure because every node in the cluster is identical.
- Read and write throughput both increase linearly as new machines are added.
- Apache Cassandra is optimized for high write throughput.
- Even when an entire data center goes down, the data is safe.
- Tunable write and read consistency (choice between CP and AP)
- Supports secondary indexes
- Uses its own query language CQL similar to SQL (took over Thrift).
- Very limited to what it can do though.
- Good use cases for Apache Cassandra:
- Transaction logging (retail, health care)
- Internet of Things (IoT)
- Time series data
- Any workload that is heavy on writes to the database.
- If you can’t afford any downtimes, Cassandra is your choice.
- Cassandra is in use at Comcast, eBay, GitHub, GoDaddy, Hulu, Instagram, Netflix, Reddit.
- Apple uses Cassandra with over 75,000 nodes for storing over 10PB of data.
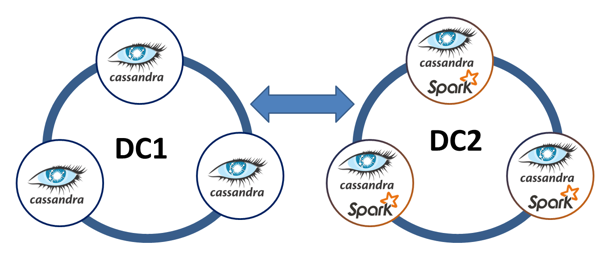
- You can replicate the whole Cassandra ring to another ring for analytics and Spark integration.
- DataStax offers a Spark-Cassandra connector.
- Allows you to read and write Cassandra tables as DataFrames.
- For example, to do analytics or data preprocessing for transactional use.
Compared to HBase
- Cassandra is AP while HBase is CP.
- Cassandra has a masterless architecture and is always available.
- HBase has a master-based one and a single point of failure.
- Cassandra replicates and duplicates data, which leads to consistency problems.
- HBase is strongly consistent.
- Cassandra’s architecture supports both data management and storage.
- HBase’s architecture is designed for data management only.
- HDFS for storage, Apache Zookeeper for server status management and metadata.
To maintain HBase, you must maintain three or four pieces of software together, whereas with Cassandra, we have just one simple process running on every single node.
- Cassandra is good at writes, whereas HBase is good at intensive reads:
- HBase doesn’t write to the log and cache simultaneously (makes writes slower)
- HBase is better at scanning huge volumes of data.
- Data model:
- Cassandra’s column is more like a cell in HBase.
- Column family in Cassandra is more like an HBase table.
- Column qualifier in HBase reminds of a super column in Cassandra.
- HBase, unlike Cassandra, has only 1-column row key.
- Cassandra vs. HBase: twins or just strangers with similar looks?
Architecture
- Decentralized peer-to-peer architecture (no master assignment)
- Employs a peer-to-peer distributed system across homogeneous nodes.
- The data is distributed among all nodes in the cluster.
- A cluster contains one or more datacenters (e.g. AWS-EAST vs AWS-WEST)
- Datacenter is a virtual or physical collection of related nodes.
- Replication is set by datacenter.
- Node is where the data is stored.
- Each node is responsible for the region between it and its predecessor on the ring.
- The region is a range of hash values.
- Handles inter-node communication through the Gossip protocol.
- So all nodes quickly learn about all other nodes in the cluster.
- Architecture in brief
- Cassandra Architecture and Write Path Anatomy
Write path
- Client read or write requests can be sent to any node in the cluster.
- That node acts as a coordinator (proxy) between the application and the cluster.
- The coordinator uses a partitioner to find the responsible replicas.
- A partitioner is a hash function that determines which node receives the row.
- The coordinator sends the write requests.
- Cassandra can be configured to prefer consistency (CP) over availability (AP):
- Consistency level controls the minimum number of nodes that must acknowledge the write.
- A consistency level of ONE means that two of the three replicas can miss the write.
- On the other hand, read consistency is controlled by the number of agreements.
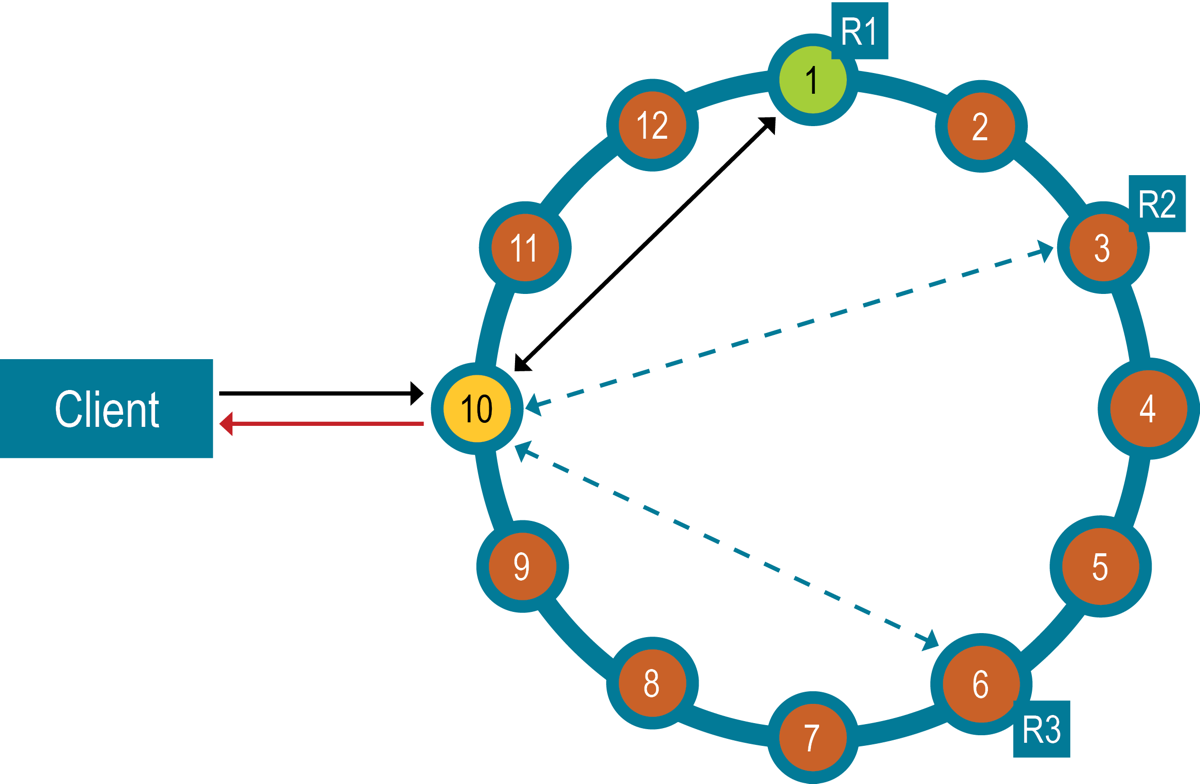
- Success means data was written to the node's commit log and the memtable.
- The commit log guarantees durability in case of a node restart or failure.
- The memtable (append-only cache) guarantees fast writes.
- After a limit, the memtable is flushed to SSTables on disk.
- How is data written?
- SSTables (Sorted String Tables, coming from BigTable) are immutable:
- This means that all updates are kept and take a lot of space.
- Can be compressed by using Compaction (just a MergeSort)
- Similarly to BigTable, Cassandra uses timestamps for version control.
- The coordinator responds to the client after receiving write acknowledgements.
Data modeling
- Requires a paradigm shift from thinking about queries in relational databases.
- Primary goals:
- Spread data evenly around the cluster.
- Minimize the number of partition reads.
- Satisfy a query by reading a single partition.
- Apache Cassandra does not allow for JOINs between tables.
- Denormalization is not just okay - it's a must for fast reads.
- One table per query is a great strategy.
- Data duplication is encouraged.
- Data modeling in Apache Cassandra is query focused:
- That focus needs to be on the WHERE clause.
- Ad-hoc queries are not a strength of Cassandra.
- In CQL, data is stored in tables containing rows of columns, similar to SQL definitions.
- Still, there are lots of differences between CQL and SQL.
- Mainly due to efficiency reasons.
- For example, JOINS, GROUP BY and subqueries are not supported.
Cassandra's model
- Each table is a distributed multi-dimensional map indexed by the PRIMARY KEY.
- All tables must be in a keyspace - keyspaces are like databases.
- PRIMARY KEY identifies the location and order of stored data.
- SIMPLE PRIMARY KEY is made up of a single column.
- The first element of the PRIMARY KEY is the PARTITION KEY.
- Distributes rows across nodes using hash function (ideally evenly)
- Each node is responsible for a range of partitions.
- COMPOSITE PARTITION KEY is a PARTITION KEY made up of more than one column.
- Used when the data stored is too large for one partition.
- This breaks data into chunks (or buckets)
- Solves hotspotting issues.
- PRIMARY KEY may also include CLUSTERING COLUMNS.
- Distributes rows across partitions.
- Ensures that the row is unique.
- Sorts rows within the partition and allows filtering on them.
- Sorting is in order of appearance in PRIMARY KEY and ascending.
- Retrieving data from a partition is then more efficient.
- Grouping data in tables using clustering columns is the equivalent of JOINs.
- Clustering columns
- Creating a table - DataStax
-- Example: Table creation in CQL
CREATE TABLE IF NOT EXISTS hello
(a int, b int, c int, d int, e int, PRIMARY KEY ((a, b), c, d));
-- (a, b) is a composite partition key
-- (c, d) is a composite clustering key
-- e is a normal column
// So, a and b are used to distribute rows among nodes,
// then each partition is sorted by c and then d.
// To get the value of e, one has first to specify the values of a, b, c and d.
// This is similar to a map<(a, b), c, d>
{
"key=(a1,b1)": {
"c=c1": {
"d=d1": ["e=e1", "e=e2", "e=e3"]
}
}
}
- Must know your queries and model the tables to your queries.
- By using the WHERE statement we know which node to go to.
- It is recommended that partitions are queried one at a time for performance implications.
SELECT *is highly discouraged, but possible withALLOW FILTERINGconfiguration.- ALLOW FILTERING explained
- Failure to specify a correct WHERE clause will result in an error.
- For example, we have to use all clustering columns in order.
- A deep look at the CQL WHERE clause
-- Example: Using WHERE clause in a wrong way
SELECT * FROM hello
-- You must restrict all partition key columns (to find the hash value)
-- With only two operators: = and IN
-- Incorrect
WHERE a = a1
WHERE a = a1 AND b > b1
-- You must specify every successive clustering key up until the key you're looking for
-- With only two operators: = and IN
-- Only the last level can use range operators
-- Incorrect
WHERE a = a1 AND b = b1 AND d > d1
WHERE a = a1 AND b = b1 AND c > c1 AND d > d1
-- You cannot filter normal columns
WHERE a = a1 AND b = b1 AND c = c1 AND d = d1 AND e = e1
-- Support those queries with additional tables designed as such