Data Pipelines
- Data pipeline is a series of steps in which data is processed.
- It's typically using either ETL or ELT, or a subset of them.
- ETL is normally a continuous, ongoing process with a well-defined workflow. ETL first extracts data from homogeneous or heterogeneous data sources. Then, data is cleansed, enriched, transformed, and stored either back in the lake or in a DWH.
- ELT (Extract, Load, Transform) is a variant of ETL wherein the extracted data is first loaded into the target system. Transformations are performed after the data is loaded into the data warehouse. ELT typically works well when the target system is powerful enough to handle transformations. Analytical databases like Amazon Redshift and Google BigQ.
- ETL Vs ELT: The Difference Is In The How
- Ensuring the quality of data through automated validation checks is a critical step.
- Data validation is the process of ensuring that data is present, correct & meaningful.
- For example: Ensuring that the number of rows in Redshift match the number of records in S3.
- Data pipelines provide a set of logical guidelines and a common set of terminology.
- A conceptual framework can help in better organizing day-to-day data engineering tasks.
- Data lineage describes the discrete steps involved in the creation, movement, and calculation of that dataset.
- Enables data engineers and architects to track the flow of this large web of data.
- Builds confidence in users that the data pipelines is designed properly.
- Helps organizations surface and agree on dataset definitions.
- Makes locating errors more obvious.
- A curated list of awesome pipeline toolkits inspired by Awesome Sysadmin
Apache Airflow

- Apache Airflow is an open-source, DAG-based, schedulable, data-pipeline framework that can run in mission-critical environments.
- Airflow was developed at Airbnb in 2014 and later open-sourced to Apache Software Foundation.
- Hundreds of companies have successfully integrated Airflow.
- A few highlights include HBO, Spotify, Lyft, Paypal, Google and Stripe.
- Has a rich and vibrant open source community.
- Airflow pipelines are defined as code and that tasks are instantiated dynamically.
- Allows to write DAGs in Python that run on a schedule and/or from an external trigger.
- Has a simple API for integrating third-party tools.
- Operators and hooks for common data tools like Apache Spark can be found in Airflow contrib
- Provides a web-based UI to visualize and interact with data pipelines.
- Data consumers can use the UI to see how and when their data was produced.
- The following components can be used to track data lineage:
- Rendered code tab for a task, graph view for a DAG, and historical runs under the tree view.
- But note: Airflow does not keep a record of historical code changes. For each change, it's better to create a new DAG to not be confused as history changes over time.
- Monitoring:
- Airflow can be configured to send emails on DAG and task state changes.
- Notifications can be sent individually for both entire DAGs or tasks.
- Airflow can send system metrics using a metrics aggregator called statsd
- Statsd can be coupled with metrics visualization tools like Grafana
- These systems can be integrated into your alerting system, such as pagerduty
Compared to Luigi
- Which is a better data pipeline scheduling platform: Airflow or Luigi?
- Workflow Processing Engine Overview 2018
- Luigi vs Airflow vs zope.wfmc: Comparison of Open-Source Workflow Engines
Architecture
- The five main components are the scheduler, workers, web server, queue, and database.
- Scheduler monitors all DAGs and tasks, and triggers the tasks whose dependencies have been met.
- Tasks without incoming dependencies are started first.
- Monitors and stays in synchronization with a folder for all DAG objects.
- Periodically inspects tasks to see if they can be triggered.
- Workers are daemons that run and record the outcome of individual pipeline tasks.
- Workers pull from the work queue when it is ready to process a task.
- Once the worker has finished the task, its status is recorded by the scheduler.
- Once all tasks have been completed, the DAG is complete.
- The metadata database stores the state of tasks and workflows.
- Also stores credentials, connections, history, and configuration.
- Airflow components interact with the database with the Python ORM, SQLAlchemy.
- Web interface provides a control dashboard for users and maintainers.
- The web interface is built using the Flask web-development micro-framework.
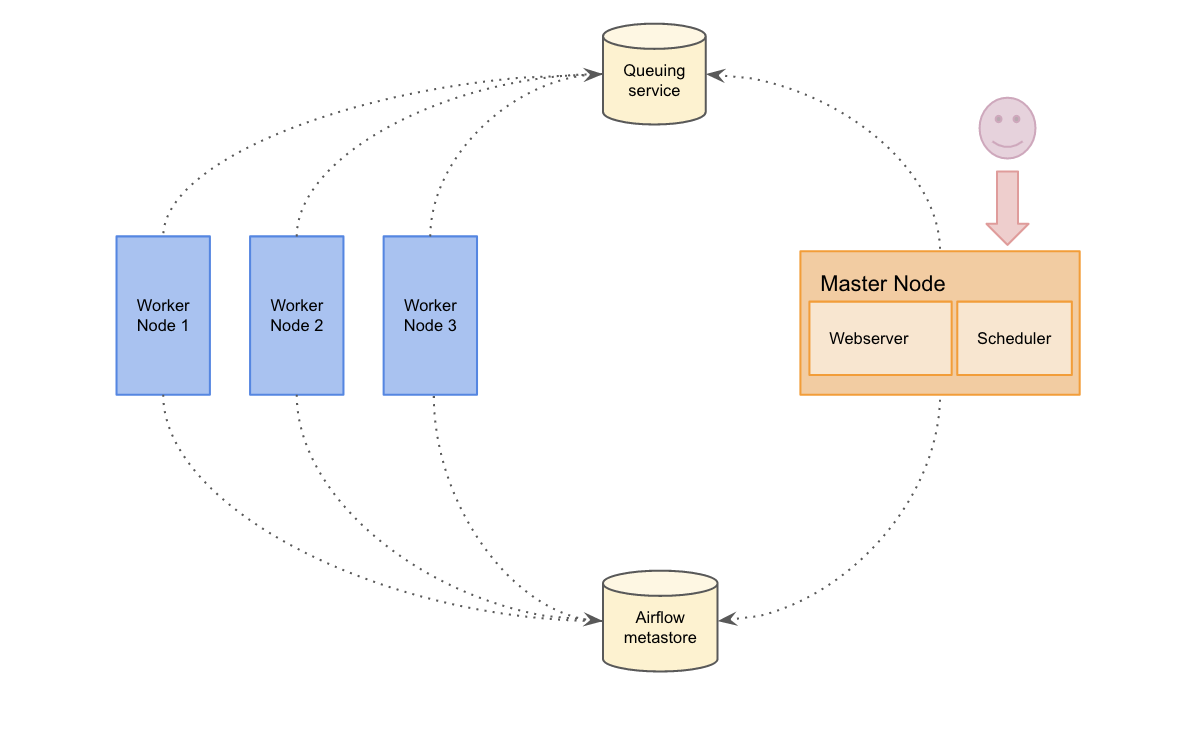
- An Airflow cluster has a number of daemons: a web server, a scheduler and one or several workers.
- Single-node architecture:
- There is a single node.
- Widely used in case there is a moderate amount of DAGs.
- Multi-node architecture:
- There are several nodes which can execute tasks in parallel.
- To scale out to multiple servers, the Celery executor mode has to be used.
- Celery executor uses Celery to distribute the load on a pool of workers.
- Celery is an asynchronous queue based on distributed message passing.
- Offers higher availability, dedicated workers for specific tasks, and scaling horizontally.
- Airflow Architecture at Drivy
Main principles
DAGs
- Directed Acyclic Graphs (DAGs) are a special subset of graphs in which the edges between nodes have a direction, and no cycles exist (nodes can't create a path back to themselves).
- Data pipelines are well expressed with DAGs.
- Nodes are the tasks in the data pipeline process.
- Edges are the dependencies or other relationships between nodes.
- Task dependencies can be specified programmatically using
a >> borb << a
# -> b_task
# / \
# a_task -> d_task
# \ /
# -> c_task
a_task >> b_task
a_task >> c_task
b_task >> d_task
c_task >> d_task
- Commonly repeated series of tasks within DAGs can be captured as reusable SubDAGs.
- Reduce duplicated code in DAGs.
- Allow for simple reusability of commonly occurring task patterns.
- Easier to understand the high level goals of a DAG.
- Bug fixes, speedups, and other enhancements can be made more quickly and distributed to all DAGs that use that subDAG.
- Drawbacks of subDAGs:
- Limit the visibility within the Airflow UI.
- Abstraction makes understanding what the DAG is doing more difficult.
- Encourage premature optimization.
- Generally, subDAGs are not necessary at all, let alone subDAGs within subDAGs.
Tasks
- Task is an instantiated step in a pipeline fully parameterized for execution.
- Tasks can have two flavors:
- Operators: execute some explicit operation.
- Sensors: check for the state of a process or a data structure.
- Boundaries between tasks should be clear and well-defined:
- Tasks should be atomic and have a single purpose: The more work a task performs, the less clear its purpose becomes. Big tasks are detrimental to maintainability, data lineage, and speed.
- Tasks should maximize parallelism: Properly scoped tasks minimize dependencies and are easier parallelized. This parallelization can offer a significant speedup in the execution of our DAGs.
- Tasks should make failure states obvious: Debugging errors is simpler if a "task" performs one task. By simply looking at Airflow UI one can pinpoint the source of error.
“Write programs that do one thing and do it well.” - Ken Thompson’s Unix Philosophy
- No information is shared between tasks - we want to parallelize as much as possible.
- But also no powerful mechanism to communicate between tasks.
- Connections can be accessed in code via hooks (e.g. S3Hook):
- Hooks provide a reusable interface to external systems and databases (e.g. S3)
- Avoids storing sensible connection strings and secrets in code.
- Airflow leverages templating to allow to “fill in the blank” with important runtime variables.
- The Zen of Python and Apache Airflow
Schedules
- Schedules determine what data should be analyzed and when.
- Benefits:
- Can reduce the amount of data that needs to be processed in a given run.
- Helps scoping the job to only run the data for the time period since the data pipeline last ran.
- Improves the quality and accuracy of the analysis by limiting the scope.
- The appropriate time period can be determined by:
- How big is the dataset?
- How frequently is the data arriving?
- How often does the analysis need to be performed?
- Which dataset requires the most frequent analysis?
- Airflow automatically schedules DAGs to satisfy each one of intervals between two dates.
- Airflow backfills for every period defined by
schedule_intervalbetween thestart_dateand now.- Useful for years of data that may need to be retroactively analyzed.
- Should be exploited to make pipelines more robust.
- DAGs may also have an
end_date- Useful or marking DAGs as end-of-life or handling data bound by two points in time.
- Useful when performing an overhaul or redesign of an existing pipeline: update the old pipeline with an
end_dateand then have the new pipeline start with theend_date
- To disable DAG run parallelization, set
max_active_runs(task parallelization is still on)- Useful when future tasks depend upon results of previous tasks.
- Used appropriately, schedules are also a form of data partitioning, which can substantially increase the speed of pipeline runs.
Data partitioning
- Data partitioning is the process of isolating data to be analyzed by one or more attributes.
- Pipelines fail more gracefully for smaller datasets and time periods.
- Makes debugging and rerunning failed tasks much simpler.
- Enables easier redos of work, reducing cost and time.
- Tasks will naturally have fewer dependencies on each other.
- Airflow will be able to parallelize execution of DAGs.
- Time partitioning: Processing data based on a schedule or when it was created.
- Great for reducing the amount of data to process.
- Also guarantee meeting timing guarantees that data consumers may need.
- Logical partitioning: Breaking conceptually related data into discrete groups for processing.
- Unrelated things belong in separate steps.
- Location partitioning: Processing data based on its location in a datastore.
- For example:
s3://<bucket>/<year>/<month>/<day
- For example:
- Size partitioning: Separating data for processing based on desired or required storage limits.
- Critical to understand when working with large datasets.
Data quality
- Data quality is the measure of how well a dataset satisfies its intended use.
- Adherence to a set of requirements is a good starting point.
- Requirements are how we can set and measure quality.
- Requirements allow both engineering and non-engineering roles to agree on the high-level method for preparing the output.
- Requirements tell engineers what the output of their data pipelines should be.
- Requirements should be defined before building the data pipeline.
- Examples of data quality requirements:
- Data must be a certain size (the number of rows in target = source)
- Data must be accurate to some margin of error.
- Data must arrive within a given timeframe from the start of execution (SLAa)
- Pipelines must run on a particular schedule.
- Data must not contain any sensitive information (e.g. GDPR compliance)
- Service Level Agreements, or SLAs, tell Airflow when a DAG must be completed by.
- For example, generate analytics that the executive team receives via email every morning.
- Slipping SLAs can be early indicators of performance problems.
- Workers might need to be scaled up if SLAs are routinely missed.