Feature Engineering
- The well-known concept of "garbage in - garbage out" applies 100% to any task in machine learning.
- A simple model trained on high-quality data can be better than a complicated multi-model ensemble built on dirty data.
- Use training set for generating learning model parameters from training data and only then transform both train and test sets according to those parameters, using the entire dataset risks information leakage.
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
Feature extraction
- Feature extraction and feature engineering: transformation of raw data into features suitable for modeling.
- Feature extraction (sklearn)
Categorical features
- Most machine learning algorithms require that their input is numerical and therefore categorical text data should be transformed into model-understandable numerical data.
- Rule of thumb: For nominal and ordinal columns try one-hot, hashing, leave-one-out, and target encoding. Avoid one-hot-encoding for high cardinality columns and tree-based algorithms. Frequency encoding works surprisingly good on many datasets. Category Encoders is a library of scikit-learn-compatible categorical variable encoders.
- Interactions of categorical features can help linear models and k-nearest neighbors.
- Smarter Ways to Encode Categorical Data for Machine Learning
Label encoding
- Encode labels with value between 0 and the number of classes-1 (
LabelEncoder) - Label encoding is better than OHE when:
- It preserves correct order of values: Label encoding is biased in a way that assumes a particular ordered relationship between categories.
- Assigns close labels to similar (in terms of target) categories: In this case tree will achieve the same quality with less amount of splits, and second, this encoding will help to treat rare categories.
- The number of categorical features in the dataset is huge: Tree-based models are able to operate on both continuous and categorical variables directly, but have to do a lot of splits to put individual categories in separate buckets to continue to improve train loss.
One-hot encoding
- The features are encoded using a one-hot (aka dummy) encoding scheme. This creates a binary column for each category and returns a dense array (
pandas.get_dummies) or a sparse matrix (OneHotEncoder). - One-hot encoding is better than label encoding when:
- Non-tree-based methods are used
- The target dependence on the label-encoded feature is very non-linear, i.e. values that are close to each other in the label-encoded feature correspond to target values that aren't close.
- One-hot encoding can lead to a huge increase in the dimensionality of the feature representations. But most of the popular libraries can work with these sparse matrices directly.
- OHE presents two problems that are more particular to tree-based models:
- The resulting sparsity virtually ensures that continuous variables are assigned higher feature importance. But if the categorical variables have few levels, then the induced sparsity is less severe and the one-hot encoded versions have a chance of competing with the continuous ones.
- A single level of a categorical variable must meet a very high bar in order to be selected for splitting early in the tree building. This can degrade predictive performance.
Feature hashing
- Addresses out-of-vocabulary issue where features are with more than a thousand categories and constantly getting new ones. OHE would consume too much (both physical and RAM) memory and require retraining after seeing new classes.
- Enables online learning (see Vowpal Wabbit): the model is capable of learning incrementally without restarting the entire process.
- Hash functions share the same common characteristics:
- If we feed the same input to a hash function, it will always give the same output.
- The choice of hash function determines the range of possible outputs, i.e. the range is always fixed.
- Hash functions are one-way: given a hash, we can’t perform a reverse lookup to determine what the input was.
- Hash functions may output the same value for different inputs (collision)
- There are a couple of considerations:
- Reverse lookups (output to input) aren’t possible and so the model lacks interpretability.
- Collisions can happen, but if you choose your vector size (make it as large as possible) and hash function carefully, the odds of this happening is negligible, and even if it does, it usually doesn’t affect learning (or accuracy) that much.
- Don’t be tricked by the Hashing Trick: If you can choose the hashing space on a per feature basis, use \(k^2\) for features with less than a thousand categories and \(20k\) for the others. If you want to control for collisions as a proportion \(r\) of the features, then use \(n=k/r\).

Mean encoding
- Encoding categorical variables with a mean target value (and also other statistics) is a popular method for working with high cardinality features, especially useful for tree-based models.
- Tackles an inability to handle high cardinality categorical variables for trees with limited depth.
- While label encoding gives random order and no correlation with target, mean encoding helps separating target classes.
- The more complicated and non-linear feature-target dependency, the more effective is mean encoding.
- Regularization reduces target variable leakage during the construction of mean encodings:
- KFold scheme (implemented in H20):
- Use just a part of examples of a category to estimate the encoding for that category. For this, split the data into \(k\) folds and for each example, estimate it's encoding using all folds except the one that the example belongs to.
- Usually decent results with 4-6 folds and \(\alpha=5\)
- Doesn't handle extreme situations like LOO well
- Expanding mean scheme (implemented in CatBoost):
- Fix some random permuation of rows and for each example estimate the encoding using target mean of all the examples before the estimated one.
- Expanding mean regularization works well only on bigger datasets
- Least amount of leakage but can also add too much noise
- Additive smoothing (Bayesian method, used by IMDB):
- Move encodings of rare categories closer to the global mean $$\large{\frac{mean(target)\times n_{rows}+globalmean\times\alpha}{n_{rows}+\alpha}}$$
- The hyperparameter \(\alpha\) controls the amount of regularization and is the category size we trust
- The main drawback: every category will be encoded with a distinct real number, that still allows the model to put any category in a distinct leaf and set an extreme target probability for the leaf.
- Only works together with some other regularization method
- KFold scheme (implemented in H20):
- Correct validation scheme: Split the data into train and validation, estimate encodings on the train, apply them to the validation, and then validate the model on that split. Always take into account time component. That way we avoid target variable leakage.
- Regression task is more flexible and allows us to calculate other statistics such as median, percentiles, standard deviation, and distribution bins of the target variable.
- Multi-class tasks require us to create \(n\) different encodings for \(n\) different classes, or treat them in one-vs-all fashion.
- By inspecting a random forest, we can extract candidates for interactions. We can iterate through all the trees in the model and calculate how many times each feature interaction appeared. The most frequent interactions are probably worthy of mean encoding. For example, we can concatenate two feature values and mean encode resulting interaction.
- Mean (likelihood) encoding: a comprehensive study
Text
Tokenization
- Tokenization is the act of breaking up a sequence of strings into pieces.
- Simply splitting by a delimeter (such as blank) can lose some of the meaning, e.g., "Los Angeles".
- The Art of Tokenization
Normalization
- Text preprocessing is not directly transferable from task to task.
- Usually done with
nltk(Natural Language ToolKit) - Lowercasing:
- While lowercasing is generally helpful, it may not be applicable for all tasks (e.g., code snippets).
- Stemming:
- Stemming is the process of reducing inflection in words to their root form ("troubled", "troubles" to "trouble"). The root in this case may not be a real root word, but just a canonical form of the original word ("saw" to "s").
- The method is useful for dealing with sparsity issues, standardizing vocabulary, and in search applications, but only marginally helps improving classification accuracy.
- Lemmatization:
- Lemmatization on the surface is very similar to stemming but actually transforms words to the actual root ("saw" to "see").
- Provides no significant benefit over stemming.
- Stop-word removal:
- Stop words may be removed to avoid them being used as signal for prediction ("the", "is")
- While effective in search and topic extraction, showed to be non-critical for classification.
- Normalization:
- Text normalization is the process of transforming text into a standard form (“gooood”, “gud” to “good”).
- It is important for noisy texts such as social media comments, text messages and comments to blog posts.
- How to improve sentiment classification accuracy by ~4%
- Noise Removal
- This includes punctuation, special characters, numbers, html formatting, domain-specific keywords, etc.
Vectorization
- As with categorical features, we first need to turn the text content into numerical feature vectors.
- A corpus of documents can be represented by a matrix with one row per document and one column per token (usually a sparse representation with
scipy.sparse). - Bag of words or Bag of n-grams (BoW,
CountVectorizer):- Looks at the histogram of the words within the text, disregarding grammar and word order but keeping multiplicity.
- A collection of unigrams cannot capture phrases and multi-word expressions, so use n-grams, which can help utilize local context around each word. N-grams features are typically sparse.
- Even though BoW representations provide weights to different words they are are unabled to capture the word meaning.
- Tf-idf (
TfidfVectorizer):- Transforms the output of a BoW vectorizer with the frequency of a term adjusted for how rarely it is used.
- This approach to scoring is called term frequency (TF) - inverse document frequency (IDF), where IDF scales features inversely proportionally to a number of word occurrences over documents. $$\large{w_{i,j}=tf_{i,j}\times{\log{(\frac{N}{df_i})}}}$$
- Just by taking the cosine between TF-IDF vectors we can retrieve relevant similar documents with higher accuracy than TF alone.
- But very short texts are likely to have noisy TF-IDF values so a binary BoW vectorizer is more stable.
- Hashing trick (
HashingVectorizer):- In practice, hashing simplifies the implementation of BoW models and improves scalability.
- But it does not provide IDF weighting as that would introduce statefulness in the model.
- Distributional embeddings:
- Each embedding vector is represented based on the mutual information it has with other words.
- Smaller vectors, values in vector rarely interpreted, words with similar meaning often have similar embeddings.
- Fixed embeddings (Word2Vec, Glove and FastText) are context-insensitive vectors trained on a large corpus directly for downstream tasks.
- Contextual embeddings (ELMo, BERT) require a model for generating word/sentence embeddings.
- Sentence vectors may be encoded through a linear weighted combination of the word vectors.
Date features
- Cyclical trends:
- Periodicity or seasonality
- Encoding cyclical continuous features into 2 dimensions via sine and cosine transformations helps linear models. Note that it distorts tree-based algorithms that split on a single dimension at a time and distance-based algorithms since splitting into two dimensions effectively double-weights the cyclic feature.
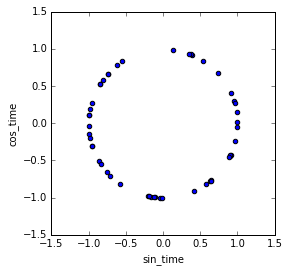
Credit
- Acyclical trends and moving averages
- Time since: Can be row-independent moment (timestamp) or row-dependent (since the last event or before the next one)
- Append external information such as state holidays
- Date variable interactions
Time series
- A useful library that automatically generates features for time series: tsfresh
Web data
- Usually there is (a wealth of) information about the user's User Agent.
- We can extract the operating system, make a feature "is_mobile", look at the browser, etc.
- IP-address can unveil the country, city, provider, and connection type (mobile/stationary).
- Extract even fancier features like suggestions for using VPN
Geospatial data
- Geospatial data is often presented in the form of addresses or coordinates of (latitude, longitude).
- Geocoding:
- There are two mutually-inverse operations: geocoding (address -> coordinates) and reverse geocoding.
- There are universal libraries like geopy that act as wrappers for external services such as Google Maps.
- Consider using a local version of OpenStreetMap if you have big data.
- Some coordinates may be erroneous:
- The position can be incorrect due to GPS noise or bad accuracy in places like tunnels.
- If the data source is a mobile device, the geolocation may be determined by WiFi networks (leads to teleportation).
- The point is usually located among infrastructure:
- Calculate distance to the nearest POI.
- Translate a map into a grid, within each square find the most interesting POI and add the distance to that point.
- Another major approach is to calculate aggregated statistics for objects surrounding a POI.
- Organize data points into clusters and use centroids as points.
- When training decision trees from coordinates, add slightly rotated coordinates as new features to help a model make more precise selections on the map. Ideally, the scatterplot with latitude and longitude on the axes should build a vertical line separating the values.
Images
- Image embeddings:
- Similar to word embeddings, extract image embeddings from hidden layers of a neural network.
- Embeddings from later layers are better to solve tasks similar to ones the network was trained on.
- Fine-tuning and data augmentation are often used in competitions where there is no other data except images.
- Features generated by hand are still very useful, for example "the average value of the pixel" to account for brightness.
- We may also try to extract features from meta-information, such as resolution, geographic coordinates of shooting, etc.
- If there is text on the image, check out pytesseract.
Feature transformation
- Feature transformation: transformation of data to improve the accuracy of the algorithm.
- Advanced techniques:
- Concatenate dataframes produced by different pre-processings, or ensembling models from different pre-processings.
- Preprocessing data (sklearn)
Missing values
- A hidden missing value can have types such as NaN, empty string, -1 (replacing missing values in [0, 1]), a very large number, -99999, 999. It can be investigated by browsing histograms for unusual peaks.
- Imputation is mostly a preferred choice over dropping variables, since it can lead to loss of important samples and a quality decrease.
- Different methodologies to data imputation:
- Impute with a constant (-999, -1) outside a fixed value range (for tree-based models).
- Impute with the feature mean (or median) if it takes no advantage of the time series characteristics or relationship between the variables. Otherwise, perform linear interpolation and seasonal adjustment to reconstruct values based on nearby observations.
- Reconstruct them (for example train a model to predict the missing values)
- Adding new binary feature indicating the missing value can be benefial.
- Some models like XGBoost and CatBoost can deal with missing values out-of-box. These models have special methods to treat them and a model's quality can benefit from it.
- Do not fill NaNs before feature generation, as this can pollute the data and screw the model.
- How to Handle Missing Data
Feature scaling
- One family of algorithms that is scale-invariant encompasses tree-based learning algorithms.
- Some examples of algorithms where feature scaling matters are: k-nearest neighbors with an Euclidean distance measure, k-means, logistic regression, SVMs, perceptrons, neural networks if using using gradient descent/ascent-based optimization, linear discriminant analysis, principal component analysis, kernel principal component analysis.
- We want regularization to be applied to linear models coefficients for features in equal amount
- Gradient descent methods can go crazy without a proper scaling
- When in doubt, just standardize the data, it shouldn't hurt.
- Also we shouldn't simply remove outliers, since it often produces a distorted view of the world in which nothing unusual ever happens, and overstates the accuracy of the findings. Better is to treat them as missing values.
- For KNN, we can go one step further and recall that the bigger the feature is the more important it is. So, we can optimize scaling parameter to boost features which seems to be more important.
Standardization
- The result of standardization (or Z-score normalization) is that the features will be rescaled so that they'll have the properties of a standard normal distribution.
- It's a general requirement for the optimal performance of many machine learning algorithms.
- Required if the algorithm involves the calculation of distances between points or vectors.
StandardScalercannot guarantee balanced feature scales in the presence of outliers.- Standard Scaling does not make the distribution normal in the strict sense. $$\large{z=\frac{x_i-\mu}{\sigma}}$$
Normalization
- In this approach, the data is scaled to a fixed range - usually 0 to 1.
- The cost of having this bounded range - in contrast to standardization - is that we will end up with smaller standard deviations, which can suppress the effect of outliers.
- As
StandardScaler,MinMaxScaleris very sensitive to the presence of outliers. $$\large{x_{\text{scaled}}=\frac{x-x_{\text{min}}}{x_{\text{max}}-x_{\text{min}}}}$$
Log-normal transformation
- Log transform helps to handle skewed data and the distribution becomes more approximate to normal (
np.log1p). - Apply a log-normal transformation to any distribution with a heavy right tail.
- This transformation is non-linear and will move outliers relatively closer to other samples.
- The optimal power transformation is found via the Box-Cox Test
- Q-Q plot for the distribution after taking the logarithm should look like a smooth diagonal line.
Winsorization
- The main purpose of winsorization is to remove outliers by clipping feature's values.
- For example, we can clip for 1st and 99th percentiles
Rank transformation
- By ranking the data, the impact of outliers is mitigated: regardless of how extreme an outlier is, it receives the same rank as if it were just slightly larger than the second-largest observation (
scipy.stats.rankdata)
Feature selection
- Feature selection: removing unnecessary features.
- Why would it even be necessary to select features?
- The more data, the higher the computational complexity.
- Some algorithms take noise (non-informative features) as a signal and overfit.
- Drop duplicate columns and rows (but ask yourself why are they duplicated?)
- Statistical approaches:
- Features with low variance are worse than those with high variance (
VarianceThreshold) - There are other ways that are also based on classical statistics.
- Features with low variance are worse than those with high variance (
- Another approach is to use some (simple) baseline model for feature evaluation:
- If features are clearly useless in a simple model, there is no need to drag them to a more complex one.
- The most reliable but computationally complex method is grid search.
- Feature selection (sklearn)
- Easy Feature Selection pipeline