Some datasets such as transactional data have multiple rows for an instance.
Treat data points as dependent on each other.
Group by a categorical feature and calculate various statistics such as sum and mean (e.g., mean encoding).
To group by a numeric feature apply binning. Binning can be applied on both categorical and numerical data to make the model more robust and prevent overfitting, however, it has a cost to the performance.
For aggregating categorical features either:
Select the label with the highest frequency
Make a pivot table
Apply groupby operation after one-hot-transforming the feature.
Distance-based features
Perform a groupby operation on instance neighborhoods (not only geodesic).
More flexible but harder to implement:
(optional) Mean encode all variables to create a homogeneous feature space.
Calculate \(N\) nearest neighbors with some distance metric (e.g., Bray-Curtis).
Calculate various statistics based on the nearest \(K\) neighbors.
Examples:
Mean target of nearest 5, 10, 15, 500, 2000 neighbors
Mean distance to 10 closest neighbors (with target 0/1)
For pairs of text features calculate:
The number of matching words
Cosine distance between their TF-IDF vectors
Distance between their average word2vec vectors
Levenshtein distance
k-NN
K-nearest neighbors is a non-parametric method used for classification and regression.
Although k-NN belongs to the family of ML algorithms, it does not learn anything.
k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification.
The algorithm searches for \(k\)-nearest training samples using a distance metric.
Regression: takes the average of the values.
Classification: classified by a plurality vote.
Larger values of \(k\) reduce noise but also make class boundaries less distinct.
Very simple to understand and equally easy to implement.
A non-parametric algorithm which means there are no assumptions to be met.
Given that it is a memory-based approach, it immediately adapts as new training data is collected.
Allows the algorithm to respond quickly to changes in the input during real-time use.
Works for multi-class problems without any extra efforts.
Can be used both for classification and regression problems.
Gives the user flexibility to choose the distance metric.
Cons
Its speed declines with the increase in the size of the dataset.
Suffers under curse of dimensionality: works only well for a small number of input variables.
For high-dimensional data, dimension reduction is usually performed.
Requires features to be scaled for certain distance criteria (e.g. Euclidean, Manhattan)
Doesn’t perform well on imbalanced data: a more frequent class tends to dominate the prediction.
The accuracy can be severely degraded by the presence of noisy or irrelevant features.
Select and scale features to improve classification.
Has no capability of dealing with missing values.
K-means
A very simple algorithm used in market segmentation, computer vision, and astronomy.
Performs division of objects into clusters that are “similar” inside and “dissimilar” outside.
k-means clustering aims to partition \(n\) observations into \(k\) clusters:
Select the number of clusters \(k\) that you think is the optimal number.
Initialize \(k\) points as “centroids” randomly within the data space.
Attribute each observation to its closest centroid.
Update the centroids to the center of all the attributed set of observations.
Repeat the previous steps a fixed number of times or until all of the centroids are stable.
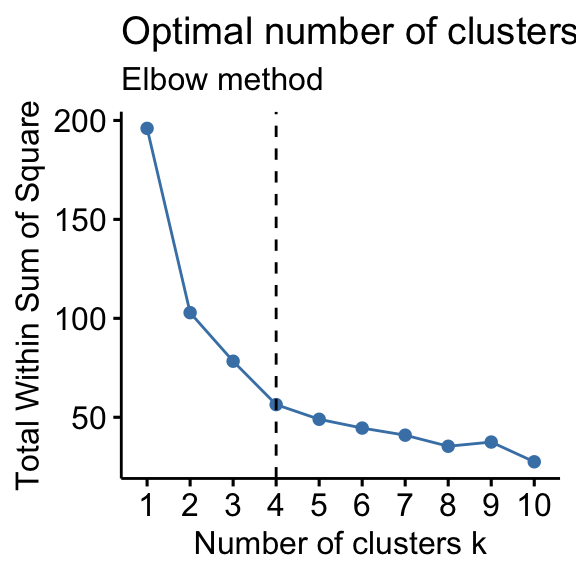
One method for choosing a "good" \(k\) is Elbow method:
The centroid distance - the average distance between data points and cluster centroids - typically reaches some "elbow"; it stops decreasing at a sharp rate.
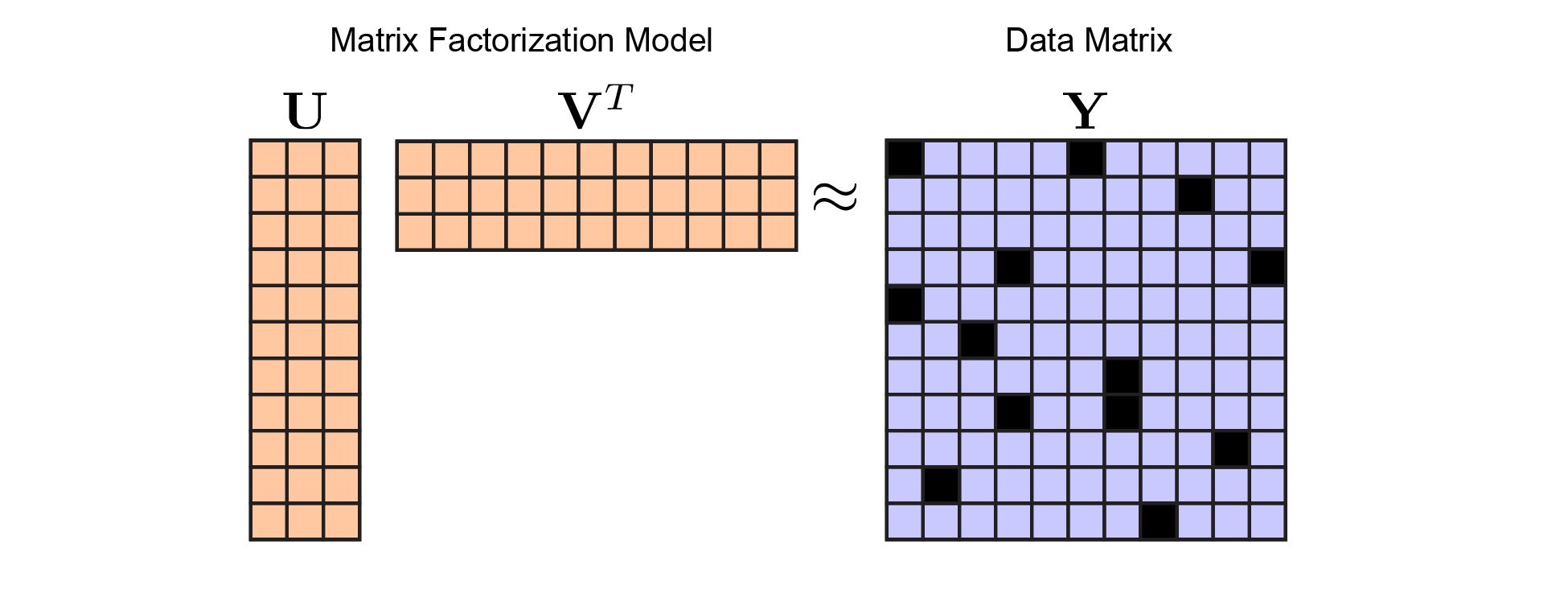
Matrix factorization is a generic approach for dimensionality reduction and feature extraction.
Useful as a dimensionality reduction technique:
Dimensionality reduction helps in filtering out not important features.
For example, for higher dimensions, clustering algorithms have a difficult time figuring out which features are the most important, resulting in noisier clusters.
Can provide additional diversity which is good for ensembles.
It is a lossy transformation which efficiency depends on the task and the number of latent factors.
The same transformation tricks as for linear models should be used.
The same parameters should be used throughout the dataset as it's a trainable transformation.
PCA (Principal Component Analysis) performs a linear mapping of the data to a lower-dimensional space in such a way that the variance of the data in the low-dimensional representation is maximized.
Features with low variance contribute less to the separation of objects.
For example, a constant feature means it doesn't have any distinguishing information.
Works by calculating the eigenvectors from the covariance matrix.
Creates components in the order of causing the most to least variance.
In practice, we would create as many components as possible and from them, choose the top \(N\) principal components that can explain 80-90% of the initial data dispersion (via the explained_variance_ratio)
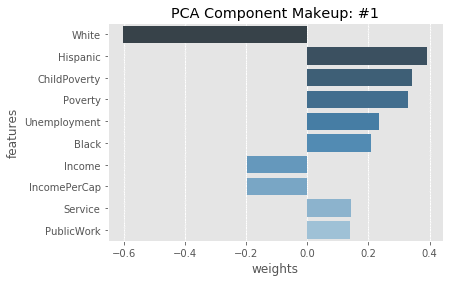
We can then examine the makeup of each PCA component based on the weightings of the original features that are included in that component.