Data Ingestion
Apache Sqoop

- Apache Sqoop is designed for transferring bulk data between Hadoop (HDFS, Hive, HBase) and RDBMS.
- In sqoop HDFS is the destination for importing data.
- Can import the result returned from an SQL query in HDFS.
- Data can be loaded directly into Hive for data analysis and also dump data into HBase.
- Kicks off MapReduce jobs to handle import and export.
- Sqoop is mainly used for parallel data transfers.
- Provides fault tolerance by using YARN framework in parallel import and export the data.
- Offers the facility of the incremental load (loading parts of table whenever it is updated)
- Can compress huge datasets using snappy method.
- Apache Sqoop is connector based architecture.
- Sqoop offers many connectors, covering almost the entire circumference of RDBMS.
- For few databases Sqoop provides bulk connector which has faster performance.
- Apache Sqoop load is not driven by events.
- Limitations:
- Scoop is atomic, meaning it cannot be paused and resumed.
- Slow because it still uses MapReduce in backend processing.
- Failures need special handling in case of partial import or export.
Example
- Move tables between MySQL and Hive.
# Import table from MySQL to Hive
$ sqoop import --connect jdbc:mysql://localhost/movielens --driver com.mysql.jdbc.Driver --table movies --hive-import
# Export table from Hive back to MySQL
$ sqoop export --connect jdbc:mysql://localhost/movielens --driver com.mysql.jdbc.Driver --table movies --export-dir /apps/hive/warehouse movies --input-fields-terminated-by '\0001'
Apache Flume

- Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
- The main design goal is to ingest huge log data into Hadoop at a higher speed.
- Acts as a mediator between data producers and the centralized stores.
- Flume is mainly used for moving bulk streaming data into HDFS or HBase.
- YARN coordinates data ingest from Apache Flume.
- Features:
- Highly distributed in nature: agents can be installed on many machines.
- Able to collect data in both real-time and batch modes.
- Provides a feature of contextual routing.
- Guarantees reliable message delivery.
- Can be scaled horizontally.
- Tunable reliability mechanisms for failover and recovery:
- Best-effort delivery does not tolerate any Flume node failure.
- End-to-end delivery guarantees delivery even in the event of multiple node failures.
Example
- Set up Flume to stream messages from one console to another.
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
# Set up Flume in the first console
$ bin/flume-ng agent --conf conf --conf-file ~/example.conf --name a1 -Dflume.root.logger=INFO,console
# In the second console type
$ telnet localhost 44444
This is a message
This is another message
# The messsages typed appear then in the first console
This is a message
This is another message
Architecture
- The transactions in Flume are channel-based where two transactions (one sender and one receiver) are maintained for each message.
- Agent is a JVM process which comprises of a Flume source, channel and sink.
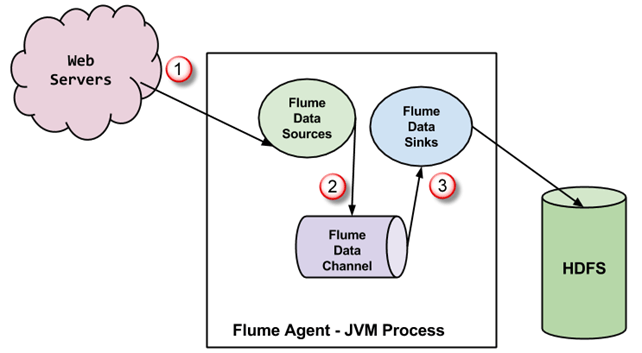
- Source:
- Receives an event and stores it into one or more channels.
- Gathering of data can either be scheduled or event-driven.
- Can optionally have channel selectors and interceptors.
- Supports spooling directory, Avro, Kafka, HTTP, and more.
- Channel:
- Acts as a store which keeps the event until it is consumed by a sink.
- Transfer via memory is faster while transfer via files is more durable.
- Has its own query processing engine to transform each new batch of data before sink.
- Sink:
- Removes the event from a channel and stores it into an external repository.
- Can be organized into sink groups.
- Supports HDFS, Hive, HBase, Elasticsearch, and more.
- Sink can only connect to one channel.
- The channel is notified to delete the message once the sink processes it.
- Using Avro, agents can connect to one another.
Apache Kafka
- Apache Kafka is a distributed streaming platform.
- Kafka was developed in 2010 at LinkedIn.
- Not just for Hadoop.
- Key features:
- Publish and subscribe to streams of records.
- Store streams of records on a Kafka cluster in a fault-tolerant way.
- Process streams of records as they occur.
- A fast, scalable, fault-tolerant, publish-subscribe messaging system.
- Can deliver in-order, persistent, scalable messaging.
- Capable of supporting message throughput of thousands of messages per second.
- Can handle these messages with very low latency of the range of milliseconds.
- Resilient to node failures and supports automatic recovery (using ZooKeeper)
- Kafka's performance is effectively constant with respect to data size.
- APIs:
- Producer API: allows an application to publish a stream of records to one or more topics.
- Consumer API: allows an application to subscribe to one or more topics and process them.
- Stream API: allows effectively transforming the input streams to output streams.
- Connector API: allows connecting topics to existing applications or data systems.
- Kafka Connect is a framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Directly competes with Apache Flume.
- Use cases:
- Ideal for communication and integration between components of large-scale data systems in real-world data systems.
- To track website activity (page views, searches, or other actions users may take)
- To produce centralized feeds of operational data from distributed applications.
- To collect physical log files off servers and put them in a central place.
- To aggregate, enrich, or otherwise transform topics into new topics for further consumption.
- Use cases
Example
- Set up Kafka to stream messages from console and consume them later.
# Create a topic
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
# Start a producer and throw some messages
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
# Start a consumer and print the messages typed previously
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
Compared to Apache Flume
- Apache Flume:
- Flume is a push system: Data is directly pushed to the the destination.
- Built around the Hadoop ecosystem.
- Does not replicate events.
- Apache Kafka:
- Kafka is a pull system: Data is pushed from producer to broker and pulled from broker to consumer.
- A general-purpose, distributed publish-subscribe messaging system.
- Can be used to connect systems that require enterprise level messaging.
- Events are available and recoverable in case of failures.
Architecture
- Runs as a cluster on one or more servers that can span multiple data centers.
- Stores streams of records in categories called topics.
- Persists all published records — whether or not they have been consumed — using a configurable retention period (for example, discard data after 2 days to free up space)
- Producers publish data to the topics of their choice.
- Consumers subscribe to one or more topics and process them.
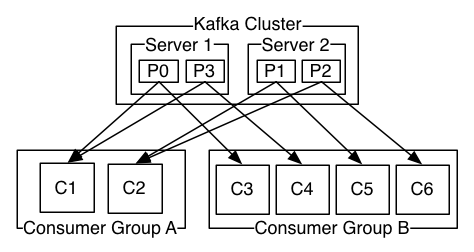
- Consumer instances can be in separate processes or on separate machines.
- Consumers must label themselves with a consumer group name.
- A topic is delivered to one consumer instance within each subscribing consumer group.
- For example, records are load-balanced over the consumers in the same group.
- A topic is a category or feed name to which records are published.
- A topic can have zero, one, or many consumers.
- Each record consists of a key, a value, and a timestamp.
- Each topic maintains a log (or multiple logs — one for each partition)
- The log is simply a data structure: time-ordered, append-only sequence of data inserts.
- The data inside of the log can be anything.
- An offset is the position of a consumer in the log:
- The offset is controlled by the consumer.
- Consumer can consume records in any order it likes.
- A partition acts as the unit of parallelism and must fit on the servers that host it.
- The partitioning is controlled by the producer.
- The partitions of the log are distributed over the servers.
- Each consumer has a "fair share" of partitions at any point in time.
- Each partition is replicated across a configurable number of servers for fault tolerance.
- Limitations:
- No record IDs: records are addressed by their offset in the log.
- No tracking of the consumers who have consumed what records.