Deep Learning Strategy
- DL strategy is useful to iterate through ideas quickly and efficiently reach the project outcome.
- Quickly prototype the first version and then improve it iteratively following the strategic guidelines.
Tips
- The cutting edge of deep learning is really about engineering, not about papers.
- The difference between really effective people in deep learning and the rest is really about who can make things in code that work properly and there’s very few of those people.
- Reading papers from competition winners is a very very good idea.
- Experiment lots, particularly in your domain area.
- Write stuff down for the you of six months ago, that’s your audience.
- It doesn’t have to be perfect.
- You can and should schedule everything, your dropout amount, what kind of data augmentation you do, weight decay, learning rate, momentum, everything. It’s very unlikely you would want the same hyperparameters throughout.
- Respect orthogonalization, which is the concept of picking parameters to tune which only adjust one outcome of the machine learning model, e.g. regularization is a knob to reduce variance.
- Don't set a random seed to see variation in your model.
- Things Jeremy says to do (Part 2)
Evaluation metrics
- A DL model generally has:
- Evaluation metrics: metrics to instantly judge the performance of models, e.g., accuracy.
- Optimizing metric: one metric to optimize for, e.g., achieve maximum accuracy.
- Satisficing metrics: certain constraints which should be upheld, e.g., time and memory usage.
- A well-defined development set and an evaluation metric speed up the iteration process.
- If you find out that your evaluation metric doesn’t accurately reflect the performance of the model, consider restating the optimization metric, e.g. through adding a weighting term to heavily penalize your classifier for misclassifying really important examples.
Splitting data
- Training set: Train the model on the training set.
- Validation/development set: After training the model, validate it on the dev set.
- Test set: When we have the final model, evaluate it on the test set in order to get an unbiased estimate of how well our algorithm is doing.
- Always make sure your data sets were normalized in the same way.
Same distribution
- Make sure that the dev/test sets come from the same distribution.
- Make sure that the dev/test sets represent the target accurately that you try to optimize for.
- Size of the dev and test sets: Use as much data as possible for training and use 1%/1% for the dev/test sets, given that your training is in the millions.
- Divide the training and dev/test sets in such a way that their distributions are similar.
Different distributions
- If the data comes from mixed data sources, create the dev/test sets with the data that you want to optimize for. For example, if you want to classify sneaker images from a phone, use a dev and test set consisting only of sneaker photos from mobile phones but feel free to use enhanced sneaker web images to train the network.
- Create a training-dev set with the same data distribution as the training set when you have a dev/test sets from different data distributions. This step helps you check if you have a variance, bias or data-mismatch problem.

Error types
| Without data mismatch | With data mismatch |
|---|---|
 |  |
Bayes error
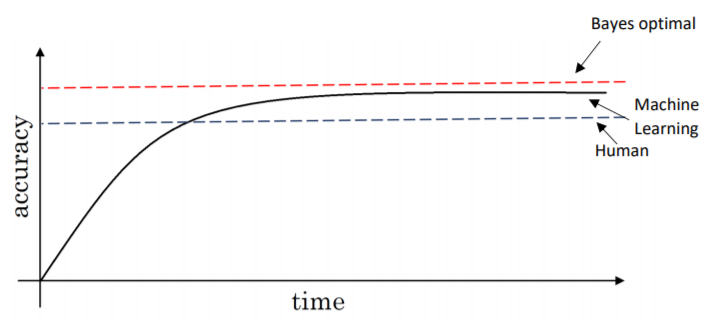
- Bayes error is the best performance that a classifier can achieve and by definition better than human-level performance.
Human-level error
- Human-level error is important metric to evaluate whether the training set suffers from bias.
- If a group of experts is able to achieve an error rate of 0.7% and a single human achieves 1% error rate, chose 0.7% as the best human-level performance and a value <0.7% as the Bayes error to test the model performance.
- Surpassing human-level performance:
- In the basic setting, DL models tend to plateau once they have reached or surpassed human-level accuracy.
- Human-level performance can serve as a very reliable proxy which can be leveraged to determine your next move when training your model.
- If your algorithm surpasses human-level performance, it becomes very hard to judge the avoidable bias because you generally don’t know how small the Bayes error is.
Training error (Bias)
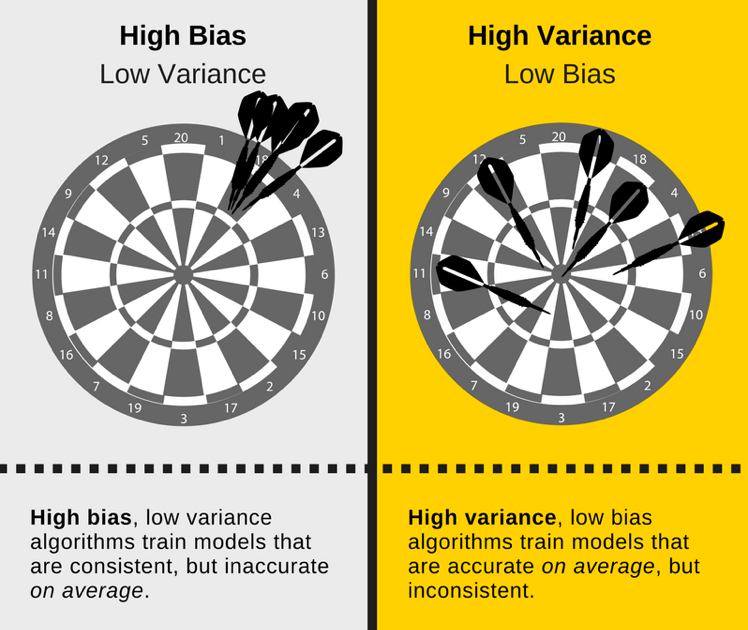
- High bias means undefitting to the training set.
- When tackling a machine learning project, the first thing we want is good performance on the training set.
- Avoidable bias: Describes the gap between training set error and human-level performance.
- Evaluate the difference between Bayes error and training set error to estimate the level of avoidable bias.
- How to solve:
- Train a more complex model.
- Train for longer time.
- Use a better optimization algorithm.
- Switch to a different architecture.
Train-dev error (Variance)
- High variance means overfitting to the training set.
- Variance is error variability, or by how much error will vary if we train the model on different sets of data.
- How to solve:
- Gather more data for training set or perform data augmentation.
- Use regularization techniques.
- Switch to a different architecture.
Dev error (Data mismatch)
- Carry out manual error analysis and understand the difference between training and dev/test sets:
- Analyze 100 misclassifies examples and batch them by reason for misclassification.
- To improve the model, it might make sense to train the network to eliminate the reason why it misclassifies a certain type of input, e.g. feed it with more foggy pictures.
- Cleaning up incorrectly labeled data: Neural networks are pretty stable to handle random misclassifications and if you eliminate misclassifications in the dev set, also eliminate them in the test set.
- Be mindful of creating artificial training data, because it could happen that you synthesize only a small subset of all available noise.
- While it may be painful to manually engineer training examples, the relative gain in performance you obtain once the parameters and the model fit well are huge and worth your while.
- Also try a new architecture.
Test error
- Test error is the degree of overfitting to the dev set.
- Reserve more data for the dev set.
Tips and tricks
Transfer learning
- There are various deep learning networks with state-of-the-art performance that have been developed and tested across domains such as computer vision and natural language processing (NLP).
- Two most popular strategies:
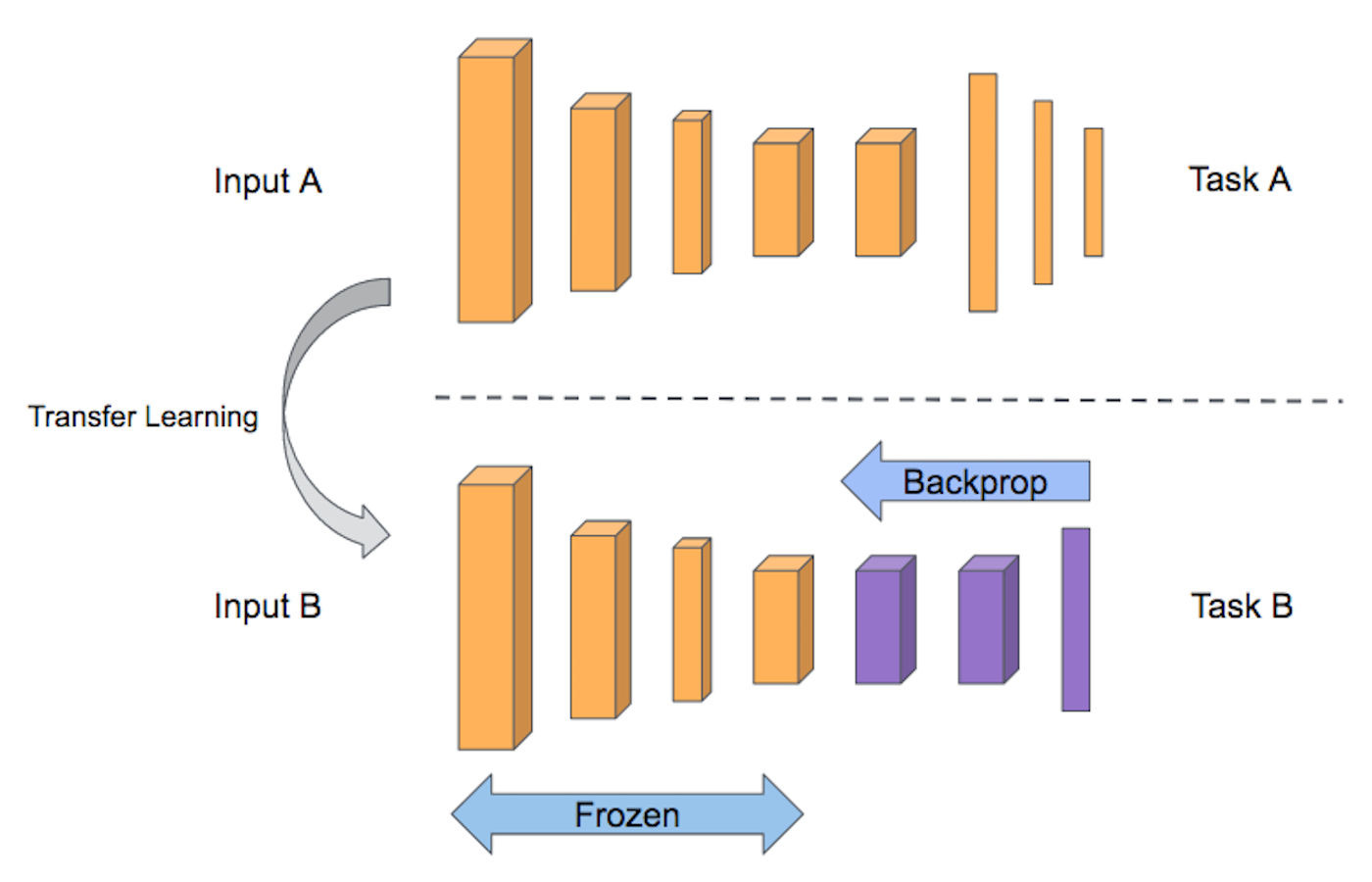
- Pre-trained models as feature extractors:
- The layered architecture allows us to utilize a pre-trained network (such as Inception V3 or VGG) without its final layer as a fixed feature extractor for other tasks.
- Fine-tuning:
- We do not just replace the final layer but also selectively retrain some of the previous layers of the base model.
- Satellite imagery and medical imagery, for example, require more lower-level fine-tuning.
- Pre-trained models as feature extractors:
- In general, we can set learning rates to be different for each layer to find a tradeoff between freezing and fine-tuning.
- A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
- Building powerful image classification models using very little data
Multitask learning
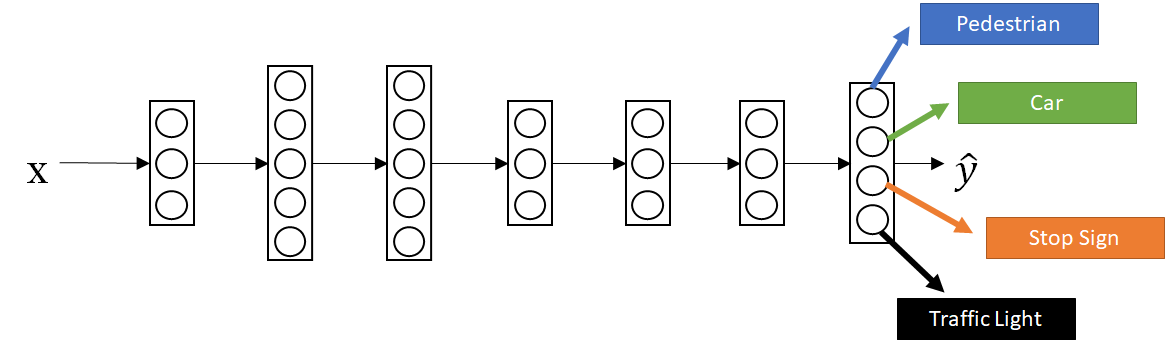
- Use a single neural network to detect multiple classes in an image, e.g. traffic lights and pedestrians for an autonomous car.
- Again, it is useful when the neural network identifies lower-level features which are helpful for multiple classification tasks and if you have an equal distribution of class data.
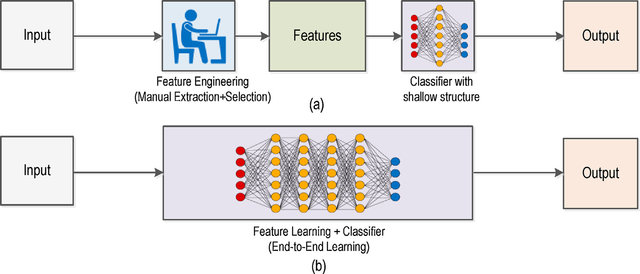
End-to-end learning
- Instead of using many different steps and manual feature engineering to generate a prediction, use one neural network to figure out the underlying pattern
- End-to-end deep learning has advantages like letting the network figure out important features itself and disadvantages like requiring lots of data, so its use really has to be judged on a case-by-case basis by how complex the task or function is that you are solving.
Data augmentation
- Suppose we are building an image classification model and are lacking the requisite data due to various reasons.
- Data augmentation refers to randomly changing the images in ways that shouldn't impact their interpretation, such as horizontal flipping, zooming, and rotating, to effectively create more data.
- These can potentially help us get more training data and hence reduce overfitting.
- But sometimes it can make some important features disappear or slow down training.
- One of the big opportunities for research is to figure out how to do data augmentation for different domains. Almost nobody is looking at that and to me it is one of the biggest opportunities that could let you decrease data requirements by 5-10x.
- Commonly data augmentation and training tasks are run on parallel CPU threads.
RandomResizeCropis something almost every Kaggle (image competition) winner have used.

Generating images
- Tips for building large image datasets
- Generating image datasets quickly
- How to scrape the web for images?
Resizing images
- One effective way to synthesize more data is to downscale/upscale images during training.
- Instead of squashing images, center-crop them to a specific size. Also, do multiple crops and use these to augment your input data, so that the original image will be split into different images of correct size.
- Padding the images with a solid color: The padding option might introduce an additional error source to the network's prediction, as the network might (read: likely will) be biased to images that contain such a padded border.
- When you're dealing with object detection and instance segmentation, anchor box sizes which are also hyperparameters need to adjust if you have a dataset with high variance in image sizes.
- Fully-convolutional networks (FCN) as well as networks with Global Average Pooling (GAP) can work regardless of the original image size, without requiring any fixed number of units at any stage, given that all connections are local.
- Make a spatial pyramid pooling layer and put it after your last convolution layer so that the FC layers always get constant dimensional vectors as input.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Mixup
- Combine two images by taking some amount of another image and some amount of another.
- For example, we might take 30% of a plane image and 70% of a dog image and then label for that combination will be 30% of a plane and 70% of a dog.
- Generalizes well to all domains and definitely something everyone should pay attention to.

Label smoothing
- When we apply the cross-entropy loss to a classification task, we’re expecting true labels to have 1, while the others 0. In other words, we have no doubts that the true labels are true, and the others are not. Is that always true? Maybe not.
- One possible solution to this is to relax our confidence on the labels.
- For example, we can slightly lower the loss target values from 1 to, say, 0.9.
- If label smoothing is nonzero, smooth the labels towards 1/num_classes.
$$\large{loss=y_k(1-\alpha)+\frac{\alpha}{K}}$$
- Helps the model to train around mislabeled data and consequently improve its robustness and performance.
- When Does Label Smoothing Help?
Test-time augmentation
- Test-time augmentation (TTA) is a form of data augmentation that a model uses during test time, as opposed to most data augmentation techniques that run during training time.
- The technique works as follows:
- augment a test image in multiple ways
- use the model to classify these variants of the test image
- average the results of the model’s many predictions
- The technique found popularity among some competitors in the ImageNet Large Scale Visual Recognition Competition
Mixed precision learning
- Mixed precision training is a technique where instead of using 32-bit floats we use 16-bit floats.
- This will speed up the training about 3x.
- It is only working on modern Nvidia drivers.
- We can’t do all in 16-bit because it is not accurate.
- Forward and backward passes are done in 16-bit because they are time consuming.
- Fixed-Precision Training Techniques Using Tensor Cores for Deep Learning
Ensemble learning
- Ensemble methods are meta-algorithms that combine several machine learning techniques into one predictive model in order to decrease variance (bagging), bias (boosting), or improve predictions (stacking).
- In order for ensemble methods to be more accurate than any of its individual members, the base learners have to be as accurate as possible and as diverse as possible.
- Ensemble Learning to Improve Machine Learning Results
Snapshot ensembles
- One of the most effective methods is to train a single neural network, converging to several local minima along its optimization path, and save the model parameters. This way, we obtain the seemingly contradictory goal of ensembling multiple neural networks at no additional training cost.
- Snapshot Ensembles: Train 1, get M for free