If each member of the jury (of size \(N\)) makes an independent judgement and the probability \(p\) of the correct decision by each juror is more than 0.5, then the probability of the correct decision \(P_N\) by the majority \(m\) tends to one. On the other hand, if \(p<0.5\) for each juror, then the probability tends to zero.
$$\large{P_N=\sum_{i=m}^{N}{\frac{N!}{(N-i)!i!}(p)^i(1-p)^{N-i}}}$$
where \(m\) as a minimal number of jurors that would make a majority.
But real votes are not independent, and do not have uniform probabilities.
Uncorrelated submissions clearly do better when ensembled than correlated submissions.
Majority votes make most sense when the evaluation metric requires hard predictions.
Choose bagging for base models with high variance.
Choose boosting for base models with high bias.
Use averaging, voting or rank averaging on manually-selected well-performing ensembles.
Averaging is taking the mean of individual model predictions.
Averaging predictions often reduces variance (as bagging does).
It’s a fairly trivial technique that results in easy, sizeable performance improvements.
Averaging exactly the same linear regressions won't give any penalty.
An often heard shorthand for this on Kaggle is "bagging submissions".
Weighted averaging
Use weighted averaging to give a better model more weight in a vote.
A very small number of parameters rarely lead to overfitting.
It is faster to implement and to run.
It does not make sense to explore weights individually (\(\alpha+\beta\neq{1})\) for:
AUC: For any \(\alpha\), \(\beta\), dividing the predictions by \(\alpha+\beta\) will not change AUC.
Accuracy (implemented with argmax): Similarly to AUC, argmax position will not change.
Conditional averaging
Use conditional averaging to cancel out erroneous ranges of individual estimators.
Can be automatically learned by boosting trees and stacking.
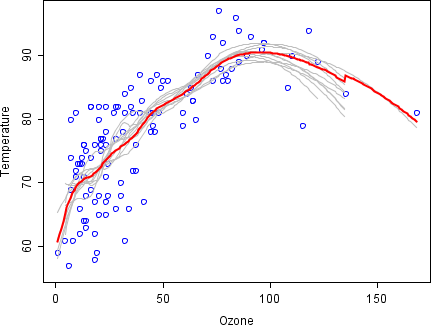
Bagging
Bagging (bootstrap aggregating) considers homogeneous models, learns them independently from each other in parallel, and combines them following some kind of deterministic averaging process.
Bagging combines strong learners together in order to "smooth out" their predictions and reduce variance.
Bootstrapping allows to fit models that are roughly independent.
Bootstrapping is random sampling with replacement.
With sampling with replacement, each sample unit has an equal probability of being selected.
Samples become approximatively independent and identically distributed (i.i.d).
It is a convenient way to treat a sample like a population.
This technique allows estimation of the sampling distribution of almost any statistic using random sampling methods.
It is a straightforward way to derive estimates of standard errors and confidence intervals for complex estimators.
For example:
Select a random element from the original sample of size \(N\) and do this \(B\) times.
Calculate the mean of each sub-sample.
Obtain a 95% confidence interval around the mean estimate for the original sample.
Two important assumptions:
\(N\) should be large enough to capture most of the complexity of the underlying distribution (representativity).
\(N\) should be large enough compared to \(B\) so that samples are not too much correlated (independence).
An average bootstrap sample contains 63.2% of the original observations and omits 36.8%.
Boosting
Boosting considers homogeneous models, learns them sequentially in a very adaptative way (a base model depends on the previous ones) and combines them following a deterministic strategy.
This technique is called boosting because we expect an ensemble to work much better than a single estimator.
Sequential methods are no longer fitted independently from each others and can't be performed in parallel.
Each new model in the ensemble focuses its efforts on the most difficult observations to fit up to now.
Boosting combines weak learners together in order to create a strong learner with lower bias.
A weak learner is defined as one whose performance is at least slightly better than random chance.
These learners are also in general less computationally expensive to fit.
Adaptive boosting
At each iteration, adaptive boosting changes the sample distribution by modifying the weights of instances.
It increases the weights of the wrongly predicted instances.
The weak learner thus focuses more on the difficult instances.
The procedure is as follows:
Fit a weak learner \(h_t\) with the current observations weights.
Estimate the learner's performance and compute its weight \(\alpha_t\) (contribution to the ensemble).
Update the strong learner by adding the new weak learner multiplied by its weight.
Compute new observations weights that expresse which observations to focus on.
$$\large{H(x)=sign{\left(\sum_{t=1}^{T}{a_th_t(x)}\right)}}$$
Gradient boosting doesn’t modify the sample distribution:
At each iteration, the weak learner trains on the remaining errors (so-called pseudo-residuals) of the strong learner.
Gradient boosting doesn’t weight weak learnes according to their performance:
The contribution of the weak learner (so-called multiplier) to the strong one is computed using gradient descent.
The computed contribution is the one minimizing the overall error of the strong learner.
Allows optimization of an arbitrary differentiable loss function.
The procedure is as follows:
Compute pseudo-residuals that indicate, for each observation, in which direction we would like to move.
Fit a weak learner \(h_t\) to the pseudo-residuals (negative gradient of the loss)
Add the predictions of \(h_t\) multiplied by the step size \(\alpha\) (learning rate) to the predictions of ensemble \(H_{t-1}\).
$$\large{H_t(x)=H_{t-1}(x)+\alpha{h_t(x)}}$$
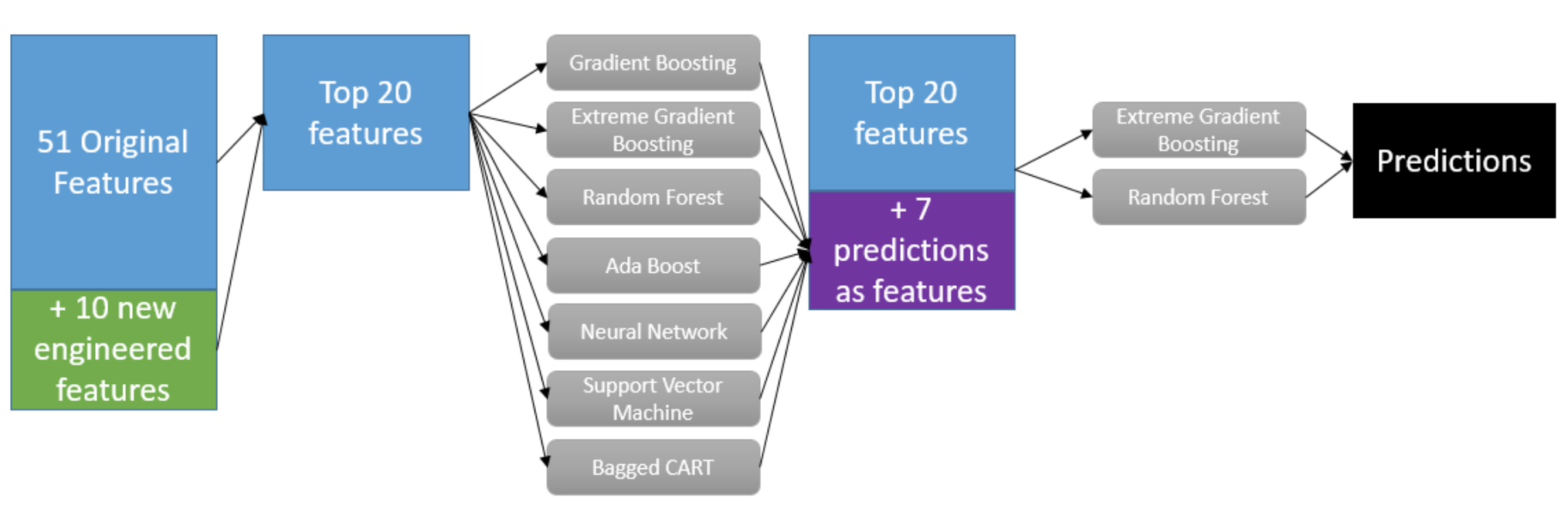
Stacking considers heterogeneous models, learns them in parallel and combines them by training a meta-model to output a prediction based on the different weak models predictions.
Stacking on a small holdout set is blending.
Stacking with linear regression is sometimes the most effective way of stacking.
Non-linear stacking gives surprising gains as it finds useful interactions between the original and the meta-model features.
Feature-weighted linear stacking stacks engineered meta-features together with model predictions.
At the end of the day you don’t know which base models will be helpful.
Stacking allows you to use classifiers for regression problems and vice versa.
Base models should be as diverse as possible:
2-3 GBMs (one with low depth, one with medium and one with high)
2-3 NNs (one deeper, one shallower)
1-2 ExtraTrees/RFs (again as diverse as possible)
1-2 linear models such as logistic/ridge regression
1 kNN model
1 factorization machine
Use different features for different models.
Use feature engineering:
Pairwise distances between meta features
Row-wise statistics (like mean)
Standard feature selection techniques
Meta models can be shallow:
GBMs with small depth (2-3)
Linear models with high regularization
ExtraTrees
Shallow NNs (1 hidden layer)
kNN with BrayCurtis distance
A simple weighted average (find weights with bruteforce)
Use automated stacking for complex cases to optimize:
CV-scores
Standard deviation of the CV-scores (a smaller deviation is a safer choice)
Complexity/memory usage and running times
Correlation (uncorrelated model predictions are preferred).
Greedy forward model selection:
Start with a base ensemble of 3 or so good models.
Add a model when it increases the train set score the most.
Multi-level stacking
Always do OOF predictions: you never know when you need to train a 2nd or 3rd level meta-classifier.
Try skip connections to deeper layers.
For 7.5 models in previous layer add 1 meta model in next layer.
Try StackNet which resembles a feedforward neural network and uses Wolpert's stacked generalization (built iteratively one layer at a time) in multiple levels to improve accuracy in machine learning problems.
Try Heamy - a set of useful tools for competitive data science (including ensembling).