Cluster Management
Hadoop YARN
- YARN (Yet Another Resource Negotiator) is responsible for allocating system resources to various applications running on a Hadoop cluster and scheduling tasks to be executed on its nodes.
- YARN is a compute layer on top of HDFS, introduced in Hadoop 2.
- YARN sits between HDFS and the processing engines being used to run applications.
- Decoupling from MapReduce 2 enabled Hadoop clusters to run interactive querying, streaming data and real-time analytics.
- Also enabled development of MapReduce alternatives (Spark, Tez) on top of YARN.
- YARN offers scalability, resource utilization, compatibility, multi-tenancy, and high availability.
- Can dynamically allocate pools of resources to applications.
- Data locality: Tries to run tasks on the same nodes which hold the relevant HDFS blocks.
- Introducing Apache Hadoop YARN
- Nomad vs. Yarn vs. Kubernetes vs. Borg vs. Mesos vs… you name it!
Components
- YARN decentralizes execution and monitoring of processing jobs.
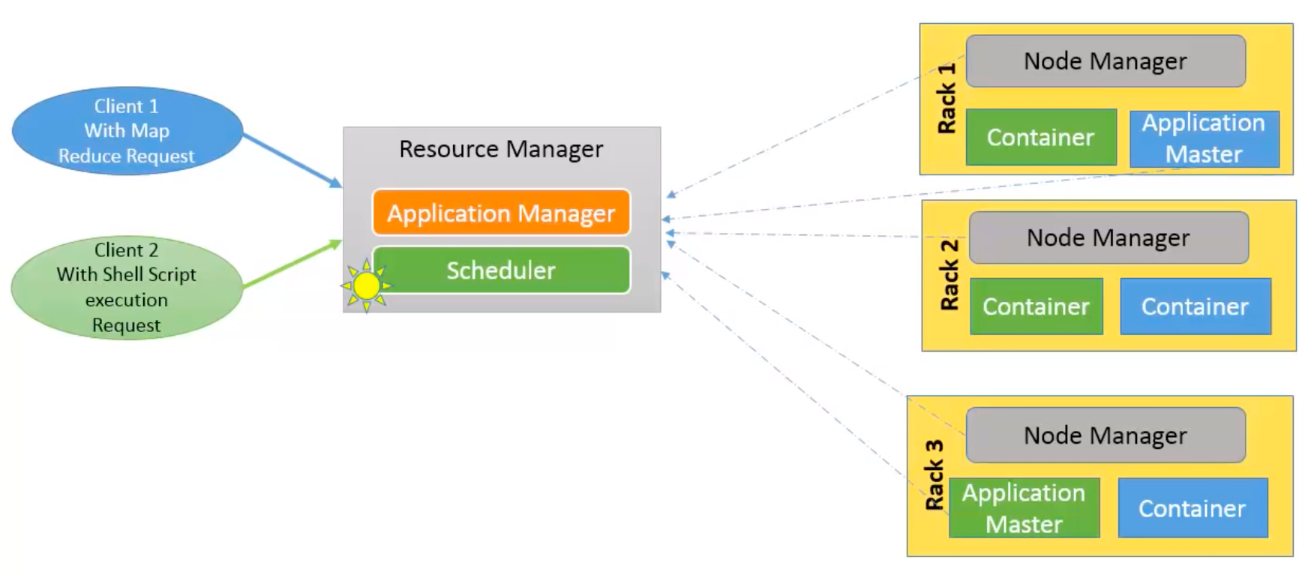
- Client:
- Submits an application.
- Contacts ResourceManager/ApplicationMaster to monitor application’s status.
- Global ResourceManager:
- Consists of Scheduler and ApplicationsManager.
- The Scheduler allocates resources to the various running applications according to constraints such as queue capacities and user limits.
- The ApplicationsManager maintains a collection of submitted applications.
- For each application, launches the ApplicationMaster.
- Per-application ApplicationMaster:
- Negotiates resources with the Scheduler.
- Works with the NodeManagers to execute and monitor the containers and their resource consumption.
- Once the application is complete, deregisters with the ResourceManager and shuts down.
- Per-node slave NodeManager:
- Launches the applications’ containers.
- Monitors their resource usage.
- Kills a container based on directions from the ResourceManager.
- Per-application Container running on a NodeManager:
- A collection of physical resources such as RAM, CPU cores and disk on a single node.
Mesos
![]()
- Apache Mesos is an open-source project to manage computer clusters.
- Abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
- Mesos is comparable to Google's Borg scheduler.
- Built using the same principles as the Linux kernel but for distributed apps.
- Focuses on resource management and decouples scheduling by allowing pluggable frameworks.
- Two-level architecture enables "application-aware" scheduling.
Mesos' ability to manage each workload the way it wants to be treated has led many companies to use Mesos as a single unified platform to run a combination of micro-services and data services together.
- Main tasks:
- Abstracts data center resources into a single pool to simplify resource allocation.
- Colocates diverse workloads on the same infrastructure.
- Automates day-two operations for application-specific tasks.
- Runs new applications and technologies without modifying the cluster manager.
- Elastically scales the application and the underlying infrastructure.
- Main features:
- Can easily scale to 10,000s of nodes.
- Fault-tolerant replicated master and agents using Zookeeper. Highly available.
- Native support for launching containers with Docker and AppC images.
- Support for running cloud native and legacy applications in the same cluster.
- HTTP APIs for developing new distributed applications, operating the cluster, and monitoring.
- Offers a built-in Web UI for viewing cluster state.
- Can allocate resources not just for big data:
- Java apps, stateless Docker containers, batch jobs, real-time analytics, and more.
- Mesos was quickly adopted by Twitter, Apple(Siri), Yelp, Uber, Netflix.
- Mesos Architecture
Compared to Hadoop YARN
- YARN is still better if the data resides on HDFS.
- Mesos is a container management system:
- Solves a more general problem than YARN.
- Apache Spark and Apache Storm can both natively run on top of Mesos.
- Spark on Mesos is limited to one executor per slave though.
- YARN is a monolithic scheduler, while Mesos is a two-tiered system:
- Makes offers of resources to your application ("framework")
- Your framework decides whether to accept or reject them.
- You also decide on your own scheduling algorithm.
- YARN is optimized for long, analytical jobs like in Hadoop.
- Mesos built to handle that as well as to handle long and short lives processes.
- Hadoop YARN may be integrated with Mesos using Myriad to intermix computing resources.
- So that spare capacities on Hadoop get used, to safe money.
Compared to Kubernetes
Kubernetes and Mesos are a match made in heaven.
- Mesos is a distributed system kernel that makes a cluster look like one giant computer system.
- Abstracts underlying hardware away and just exposes the resources.
- Contains primitives for writing distributed applications (Spark was built for Messos)
- Yet Kubernetes is one (amongst others) frameworks that can be run on Mesos.
- Kubernetes can provide the scheduling logic and Mesos can take care of running jobs.
- Kubernetes enables the Pod (group of co-located containers) abstraction, along with Pod labels for service discovery, load-balancing, and replication control.
- Mesos provides the fine-grained resource allocations for pods across nodes in a cluster.
- Mesos is being adapted to add a lot of the Kubernetes concepts.
- Docker vs. Kubernetes vs. Apache Mesos
Apache ZooKeeper
![]()
- ZooKeeper is a service for distributed systems to store configuration information.
- ZooKeeper was once a sub-project of Hadoop.
- ZooKeeper is an integral part of HBase, Apache Drill, Storm and more.
- For example, Mesos uses ZooKeeper for cluster membership and leader election.
- Based on Paxos algorithm variant called Zab.
- Used where some data needs to be carefully synchronized between client nodes.
- Which node is the master?
- Which tasks are assigned to which workers?
- Which workers are currently available?
- Feature-light: The mechanisms such as leader election and locks are not already present, but can be written above the ZooKeeper primitives.
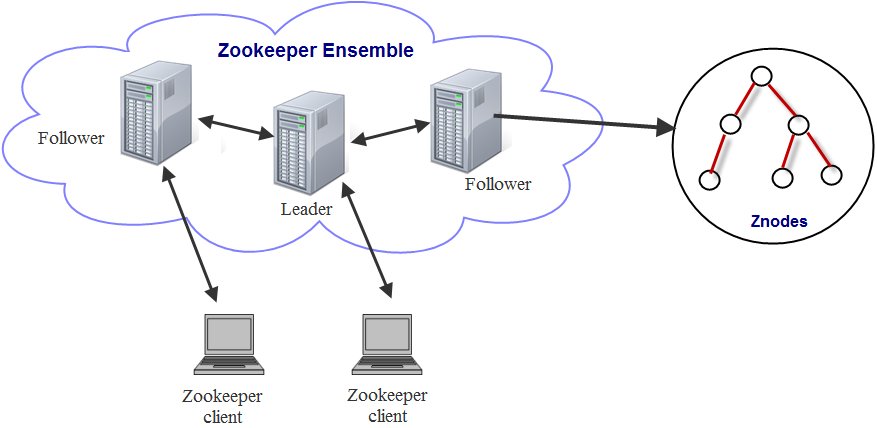
- Offers a hierarchical key-value store, which is used for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
- Really a little distributed file system with strong consistency guarantees (CP).
- A shared hierarchical name space of data registers (znodes)
- A name is a sequence of path elements separated by a slash ("/")
- Every znode can have data associated with it. For example, a znode can contain information on who the current master is.
- Persistent znodes remain stored even if master crashes.
- Ephemeral znodes are destroyed as soon as the client that created it disconnects.
- Avoids continuous polling by letting the client subscribe for notifications on a znode.
- ZooKeeper's API:
create,delete,exists,setData,getData,getChildren
- Offers high throughput, low latency, highly available, strictly ordered access to the znodes.
- Prevents becoming the single point of failure in big systems.
- It's an atomic broadcast system, through which updates are totally ordered.
- As long as a majority of the servers are available, the ZooKeeper service will be available.
- Who watches the watcher?
- Ensemble is nothing but a cluster of Zookeeper servers.
- Quorum defines the rule to form a healthy ensemble. Quorum is defined using a formula \(Q=2N+1\) where \(Q\) defines number of nodes required to form a healthy ensemble which can allow \(N\) failure nodes. Three nodes are required to tolerate a single failure.
- Healthy ensemble is a cluster with only one active leader at any point of time.
- Pros:
- This system is very reliable as it keeps working even if a node fails.
- The architecture of ZooKeeper is quite simple as there is a shared hierarchical namespace which helps coordinating the processes.
- ZooKeeper is especially fast in "read-dominant" workloads (because of the guarantee of linear writes it does not perform well for write-dominant workloads)
- The performance of ZooKeeper can be improved by adding nodes.
- Can be used in large distributed systems.
Apache Oozie

- Apache Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
- Oozie is a scalable, reliable and extensible system.
- Oozie is a Java Web-Application that runs in a Java servlet-container.
- Workflow is a collection of Hadoop actions arranged in a control dependency DAG.
- The second action can’t run until the first action has completed.
- Can chain together MapReduce, Hive, Pig, etc. but also Java programs and shell scripts.
- Other systems are available via add-ons (e.g. Spark)
- Workflow definitions are written in hPDL (a XML Process Definition Language)
- Steps to set up a workflow:
- Make sure each action works on its own.
- Make a directory on HDFS.
- Create
workflow.xmlfile and put it inside of this directory. - Create
job.propertiesdefining the variables thatworkflow.xmlneeds.
$ oozie job --oozie http://localhost:11000/oozie -config /home/maria_dev/job.properties -run
# Monitor the progress at http://localhost:11000/oozie
- Coordinator allows to define and execute recurrent and interdependent workflow jobs.
- Schedules workflow execution.
- Launches workflows based on a given start time and frequency.
- Will also wait for required input data to become available.
- Runs in exactly the same way as workflows.
- Bundle is a higher-level abstraction that will batch a set of coordinator applications.
- There is no explicit dependency among the coordinator applications in a bundle.
- But there is a data dependency: For example, by grouping a bunch of coordinators into a bundle, one could suspend them all if there is any problem with the input data.
Apache Zeppelin
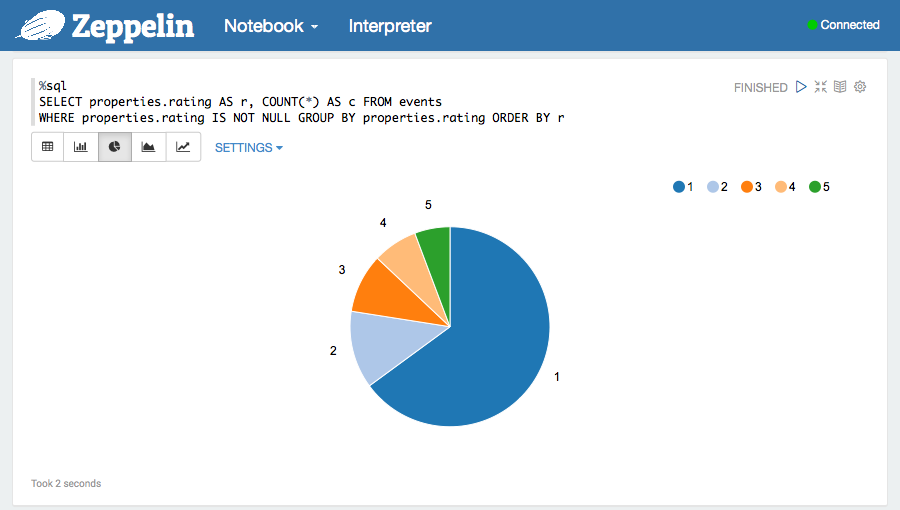
![]()
- Apache Zeppelin is a web-based notebook that enables data-driven, interactive data analytics and collaborative documents on Hadoop.
- Similar to the Jupyter Notebook that has been extremely popular in the Python community.
- Supports 20+ different interpreters such as Spark, Python, Scala, Hive, shell and markdown.
- Allows any language and data processing backend to be plugged in.
- Allows them to be mixed in the same notebook.