Word Embeddings
- Humans treat words as discrete atomic symbols:
- These encodings are arbitrary, and provide no useful information to the system regarding the relationships that may exist between the individual symbols, since their inner product is zero and the distances between them are the same.
- So, instead of a one-hot presentation, we should learn a featurized representation.
- Word embeddings are in fact a class of techniques which represent individual words as real-valued vectors in a predefined vector space, where semantically similar words are mapped to nearby points ('are embedded nearby each other').
- A word embedding is a learned representation for text where semantically similar words have similar vectors.
- In a simplified sense each dimension represents a meaning and the word’s numerical weight on that dimension captures the closeness of its association with and to that meaning.
- The beauty of representing words as vectors is that they lend themselves to mathematical operators, such as
king — man + woman = queenenabling analogy reasoning. - What Are Word Embeddings for Text?
- Word vectors for non-NLP data and research people
Dense representation
- The number of features is much smaller than the size of the vocabulary:
- Each word is represented by a real-valued vector, often tens or hundreds of dimensions.
- This is contrasted to the thousands or millions of dimensions required for sparse word representations, such as a one-hot encoding.
- One of the benefits of using dense and low-dimensional vectors is computational:
- The majority of neural network toolkits do not play well with very high-dimensional, sparse vectors.
- The other benefit of the dense representations is generalization power.
Interpretability
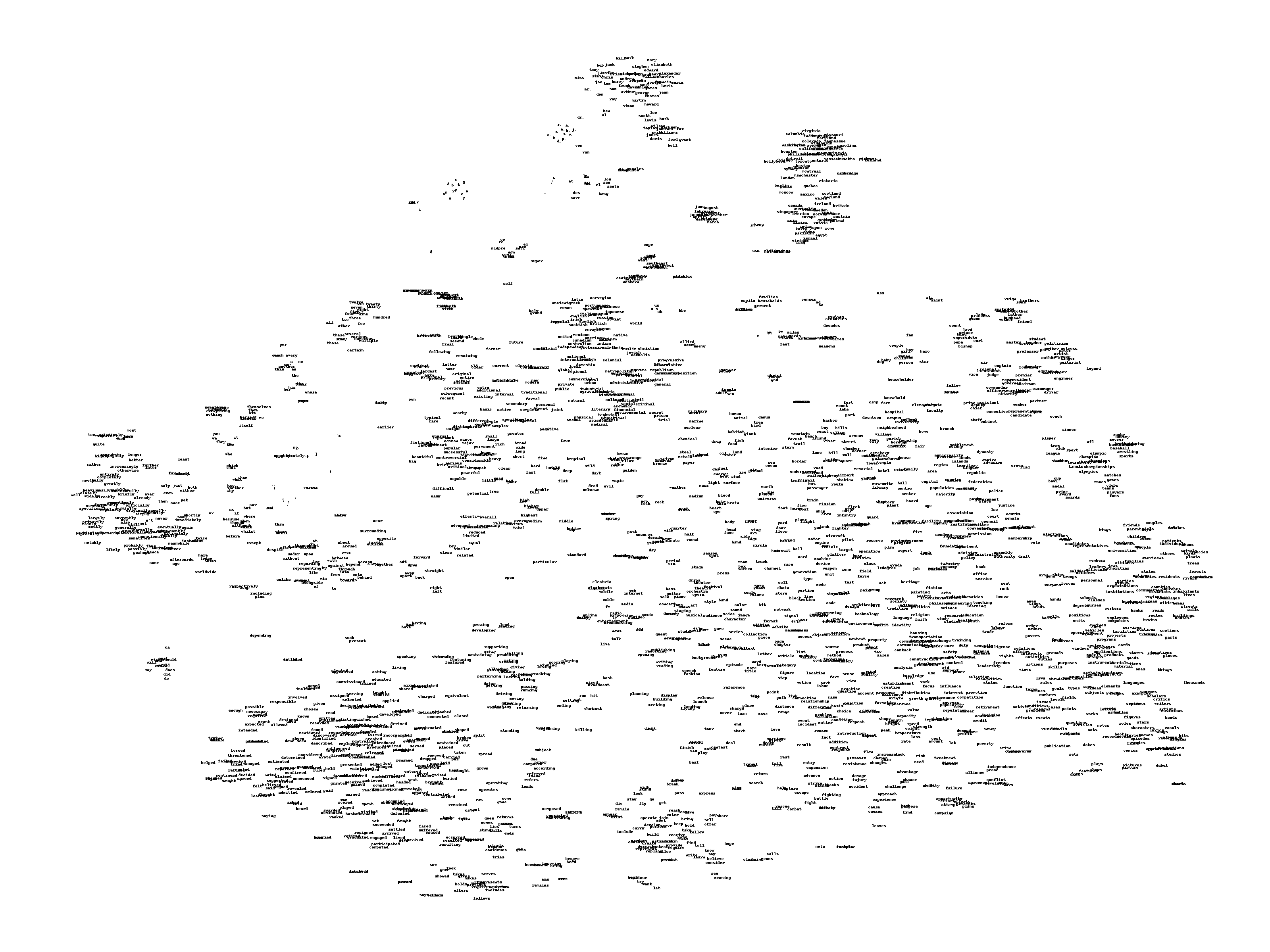
- We can visualize the learned vectors by projecting them down with t-SNE.
- We can also use cosine similarity or Euclidean distance to calculate the similarity between embeddings.
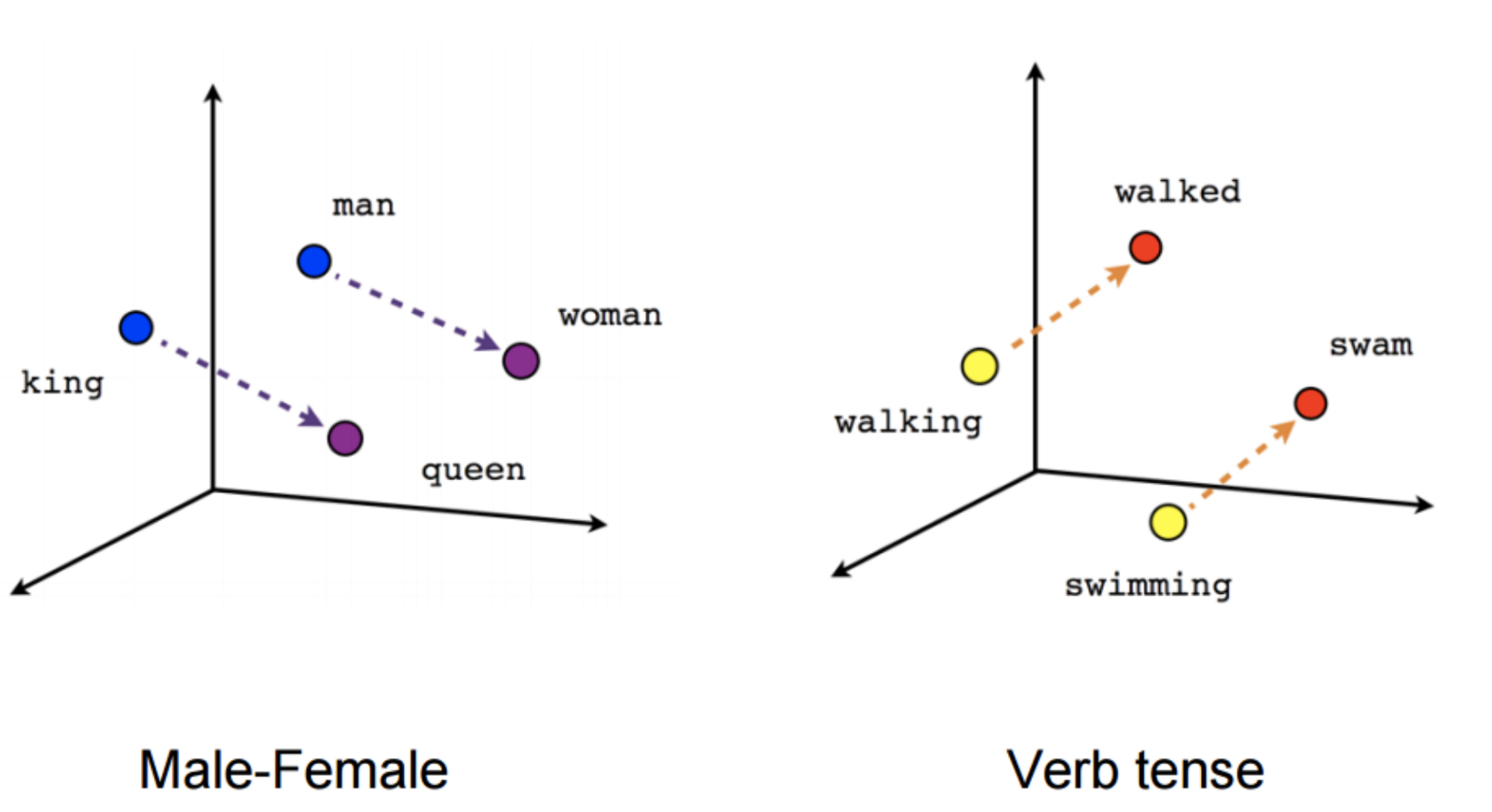
- Certain directions in the induced vector space specialize towards certain semantic relationships.
- For example, male-female, verb tense and even country-capital relationships between words.
- Sometimes, the learned embeddings may have no or combined interpretable features at all.
Usage
- Because word embeddings are very computationally expensive to train, most ML practitioners will load a pre-trained set of embeddings.
- Learn embeddings:
- Standalone: a model is trained to learn the embedding, which is saved and used as a part of another model.
- Jointly: the embedding is learned as part of a large task-specific model.
- Instead of training own embeddings from scratch, pre-trained word embeddings can be used:
- Static: the embedding is kept static and is used as a component of the model.
- Updated: the pre-trained embedding is used to seed the model, but the embedding is updated jointly during the training of the model.
- Transfer learning:
- Learn word embeddings from a large text corpus (1-100B words)
- Transfer the word embeddings to a new task with a smaller training set (say, 100k words)
- Optional: continue to finetune the word embeddings with new data
Models
- We want to build a language model so that we can predict the next word.
- The distributed representation is learned based on the usage of words. This allows words that are used in similar ways to result in having similar representations, naturally capturing their meaning.
- Word embedding methods learn a real-valued vector representation for a predefined fixed sized vocabulary from a corpus of text.

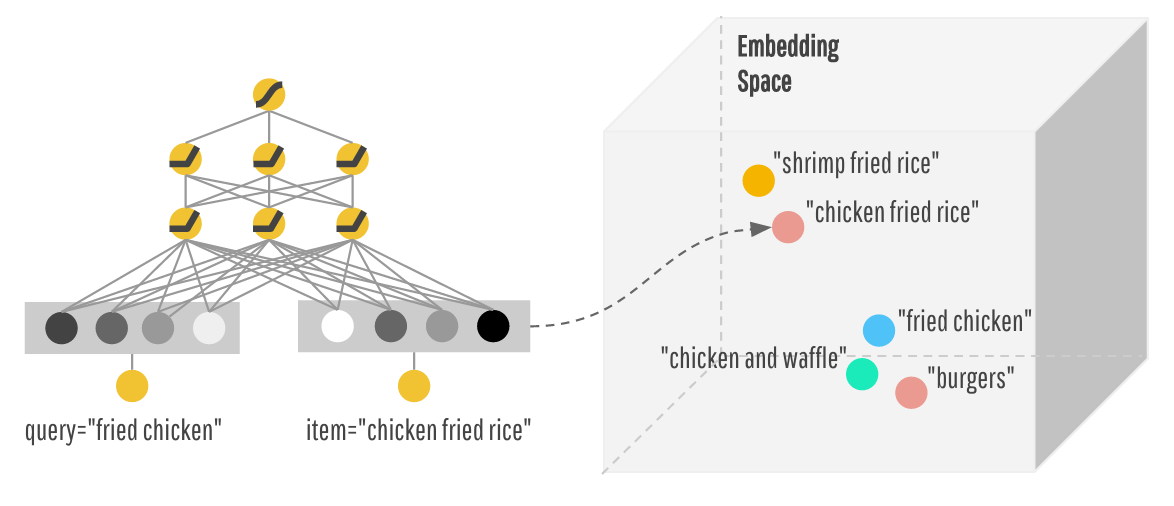
Embedding layer
- A great strength of neural networks is that they learn better ways to represent data, automatically.
- An embedding layer is a word embedding that is learned jointly with a neural network model on a specific NLP task, where one-hot encoded words are mapped to the embedding vectors.
- For example, the network will automatically learn to encode gender in a consistent way.
Word2Vec
- Word2vec builds upon distributional hypothesis:
- Words that share similar contexts tend to have similar meanings.
- A word2vec model is simply a NN with a single hidden layer that is designed to reconstruct the context of words by estimating the probability that a word is “close” to another word given as input.
- The word vector is the model’s attempt to learn a good numerical representation of the word in order to minimize the loss (error) of it’s predictions.
- Another place you may have seen this trick is in unsupervised feature learning:
- You train an auto-encoder to compress an input vector in the hidden layer, and decompress it back to the original in the output layer. After training it, you strip off the output layer (the decompression step) and just use the hidden layer - it's a trick for learning good image features without having labeled training data.
Negative sampling
- Neural probabilistic language models are traditionally trained using softmax, which is very expensive.
- Every time at computing loss we need to carry out the sum over all words in the vocabulary.
- Negative sampling allows to do something similar to the skip-gram model, but with a much more efficient learning algorithm.
- To generate the samples, pick a positive context and \(k\) negative contexts (noise words) from the dictionary.
- The samples can be picked according to empirical frequencies in words corpus which means according to how often different words appears.
- Then it is trained using a binary classification objective, which is less expensive than softmax. This objective is maximized when the model assigns high probabilities to the real words, and low probabilities to noise words.
Learning models
- Word2vec comes in two flavors, the Continuous Bag-of-Words model (CBOW) and the Skip-Gram model.
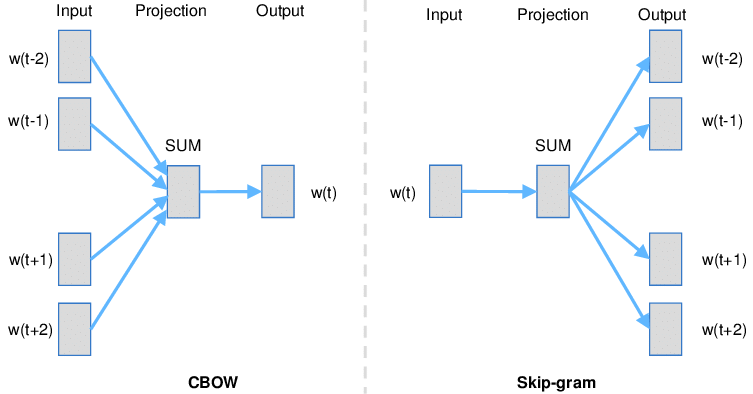
- Algorithmically, these models are similar, except that:
- CBOW predicts target words (e.g. 'mat') from source context words ('the cat sits on the'), which works well for smaller datasets.
- Skip-gram does the inverse and predicts source context-words from the target words, which works well for bigger datasets.
- Both models are focused on learning about words given their local usage context, where the context is defined by a (sliding) window of neighboring words.
- The size of the sliding window has a strong effect on the resulting vector similarities:
- Large windows tend to produce more topical similarities.
- Smaller windows tend to produce more functional and syntactic similarities.
- Word2Vec Tutorial - The Skip-Gram Model
Applications
- Text classification & chatbots
- Recommender systems and ad targeting:
- Instead of learning vectors from a sequence of words, you can learn vectors from a sequence of user actions, or sequence of songs in a playlist, etc.
Pros
- The resulting representations are surprisingly good at capturing syntactic and semantic regularities in language, and that each relationship is characterized by a relation-specific vector offset. This allows vector-oriented reasoning based on the offsets between words. For example, the male/female relationship is automatically learned.
- High-quality word embeddings can be learned efficiently (low space and time complexity), allowing larger embeddings to be learned (more dimensions) from much larger corpora of text (billions of words).
GloVe
- GloVe algorithm is an extension to the word2vec method for efficiently learning word vectors.
- Rather than using a window to define local context, GloVe constructs an explicit word-context or word co-occurrence matrix using statistics across the whole text corpus.
Pros
- GloVe, is a global log-bilinear regression model for the unsupervised learning of word representations that outperforms previous models on word analogy, word similarity, and named entity recognition tasks.