Data Lakes

- Data warehousing is a mature field with lots of cumulative experience.
- Dimensional modeling is extremely relevant to this day.
- For many organizations, data warehousing is the best way to go.
- A data lake shares the same goals of a DWH of supporting business insights beyond the day-to-day transactional data handling.
- Data lakes are the new data warehouses that evolved to cope with:
- The variety of data formats and structuring.
- The agile and ad-hoc nature of data exploration needed by data scientists.
- The wide spectrum of data transformation needed by advanced analytics.

Data warehouse is like a bottle of water - ”cleansed, packaged and structured for easy consumption” - while a data lake is more like a body of water in its natural state. Data flows from the streams (the source systems) to the lake. Users have access to the lake to examine, take samples or dive in.
Reasons
- The abundance of unstructured data, such as text, sensor data and images.
- DWH might still convert the data in the ETL process into a tabular format. But deciding on a particular form is a strong commitment without enough knowledge.
- Some data is hard to be put in a tabular format like deep JSON documents. Some data can be stored as blobs but remain useless until extraction.
- ML models need to access raw data in forms different from a star schema.
- Data analysis can also be done without a predefined schema ("schema-on-read"). Schema can be either inferred, or specified and upon read the data is checked against it.
- The rise of big data technologies, such as Apache Spark.
- They make it easy to work with files as if they were a database.
- Spark can read from files, file systems, databases, all exposed through DataFrames and SQL.
- Schema-on-Read: Querying on the fly, no database creation, no insertions.
# Example: Schema inference
# Name Department years_of_experience DOB
# Sam Software 5 1990-10-10
# Alex Data Analytics 3 1992-10-10
df = spark.read.format("com.databricks.spark.csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(path)
df.schema
# root
# |-- Name: string (nullable = true)
# |-- Department: string (nullable = true)
# |-- years_of_experience: integer (nullable = true)
# |-- DOB: string (nullable = true) -> suboptimally inferred type
- Unprecedented data volumes, such that of IoT and social data.
- New types of data analysis algorithms are gaining momentum, such as graph analytics.
- Emergence of new roles such as data scientist.
- DWH tries to serve business users with a clean, consistent and performant model.
- But data scientists need freedom (away from single rigid data representation)
Issues
- Prone to being a chaotic data garbage dump.
- Efforts are being made to put measures and practices like detailed metadata.
- Data governance is not easy to implement:
- Due to the wide accessibility of cross-department data and external data of relevance.
- Should data lake replace, offload or work in parallel with data warehouses and marts?
- Dimensional modeling continues to remain a valuable practice.
Amazon S3

- Amazon Simple Storage Service (Amazon S3) is an object storage service.
- Gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage.
- Data is stored as objects within resources called “buckets”.
- Each object is identified by a unique, user-assigned key.
- A single object can be up to 5 terabytes in size.
- Amazon S3 Concepts
- Enables running big data analytics across S3 objects with query-in-place services on AWS.
- Amazon Athena to query S3 data with standard SQL expressions.
- Amazon Redshift Spectrum to analyze data that is stored across AWS resources.
- Use S3 Select to retrieve subsets of object data, which improves query performance by up to 400%.
- Designed for 99.999999999% (11 9's) of durability and 99.99% of availability.
- The data, once you put it into S3, it's pretty much indestructible.
- Availability, Durability and Reliability
- Features:
- Provides management features to organize data and configure finely-tuned access controls.
- Supports wide range of cost-effective storage classes (based on access patterns)
- Provides security, compliance, and audit capabilities.
- Works well with AWS Lambda to log activities, define alerts, and automate workflows.
- Enables versioning to preserve, retrieve, and restore every version of an object.
- Allows using bucket names, prefixes, object tags, and S3 Inventory to categorize data.
- Enables deploying hybrid storage architectures (on-premise + S3)
- Amazon S3 Features
- S3 is an example of the first and the final data stores where data might be loaded.
Amazon EMR

- Amazon EMR is a service that uses Apache Spark and Hadoop.
- Supports tools such as Spark, Hive, HBase, Flink, and Presto.
- Can run deep learning and machine learning tools such as TensorFlow.
- Using bootstrap actions, one can add and use case-specific tools and libraries.
- Offers a scalable managed service as an easier alternative to running in-house cluster computing.
- Features:
- Pay-per-use: For a fraction of the cost of on-premise clusters (per-second billing)
- Provides fast (in minutes) and easy cluster provisioning.
- Elastic: Resources can be scaled out (more nodes) and scaled up (more powerful nodes)
- Jupyter-based EMR Notebooks for iterative development, collaboration, and data access on AWS.
- Tasks can be run on single-purpose short lived clusters that automatically scale.
- Takes care of software updates and bug fixes.
- Can configure Hadoop applications for High Availability.
- Allows for modifying Hadoop applications on the fly without re-creating the cluster.
- Amazon EMR features
Data storage options
- HDFS:
- Once ingested, the data is stored on HDFS, processed on the cluster (query-in-place), and accessed by BI or advanced analytics tools.
- The EMR cluster is created once, but can grow and is not supposed to be shutdown.
- Amazon S3:
- No HDFS, the data is stored on S3. Data is loaded into EMR for processing. Query/processing results are passed back into S3. Those results can be then accessed by other apps.
- The EMR cluster is spun on-demand, shutdown otherwise (which is cheaper)
- The data is easier-to-manage and more safe on S3.
- One can use multiple clusters to process the same data.
- Less performant than the 1. option because of longer load time.
AWS Glue
- AWS Glue is a fully managed ETL (extract, transform, and load) service.
- AWS Glue is serverless, so there’s no infrastructure to set up or manage.
- Used to build a data warehouse to organize, cleanse, validate, and format data.
- Makes the data available for querying with Athena and Redshift Spectrum.
- Consists of
- a central metadata repository known as the AWS Glue Data Catalog,
- an ETL engine that automatically generates Python or Scala code, and
- a flexible scheduler that handles dependency resolution, job monitoring, and retries.
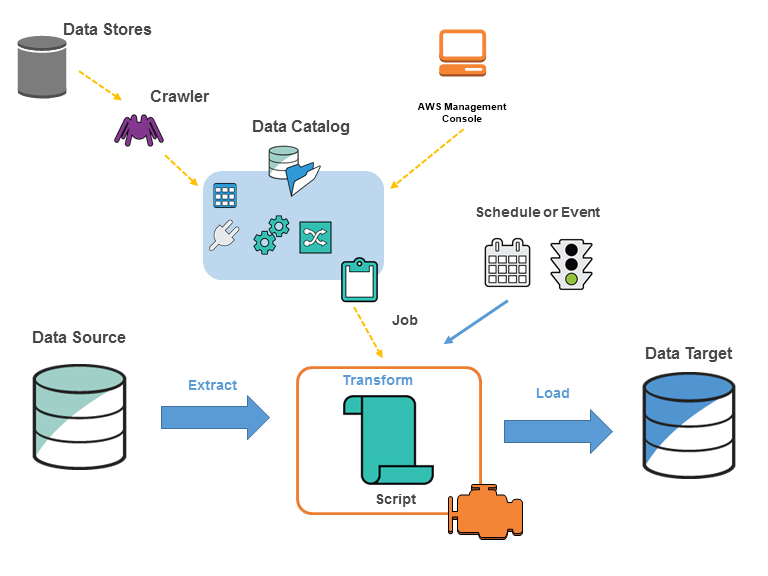
- Can process semi-structured data, such as clickstream or process logs.
- Discovers and catalogs metadata about data stores into a central catalog.
- Populates the AWS Glue Data Catalog with table definitions from crawlers.
- Crawlers call classifier logic to infer the schema, format, and data types of the data.
- The catalog is a fully managed, Apache Hive Metastore compatible, metadata repository.
- Can be used to quickly search and discover the datasets on S3.
- Generates ETL scripts to transform, flatten, and enrich the data from source to target.
- Can trigger ETL jobs based on a schedule or event.
- Can initiate jobs automatically to move the data into data warehouse.
- Triggers can be used to create a dependency flow between jobs.
- Gathers runtime metrics to monitor the activities of the data warehouse.
- Handles errors and retries automatically.
- Scales resources, as needed.
- What Is AWS Glue?
Amazon Athena

- Amazon Athena is an interactive query service to analyze data in Amazon S3 using SQL.
- Athena is serverless, so there is no infrastructure to manage.
- The technology is based on the open-source Facebook Presto or PrestoDB software.
- See the Facebook Presto function documentation for a full list of functions.

- Pay by execution time, not by machine up-time.
- Supports many file formats such as ORC, JSON, CSV, and Parquet.
- Hint: Compress, partition, or convert data to a Parquet format to get cost savings.
- Automatically executes queries in parallel to get query results in seconds, even on large datasets.
- Integrates out-of-the-box with AWS Glue Data Catalog.
- Limitations:
- No support for user-defined functions and stored procedures.
- No support for Hive or Presto transactions.
- One query at a time and five concurrent queries for each account.
- 9 Things to Consider When Choosing Amazon Athena