Object Detection
- The object detection task consists in determining the location on the image where certain objects are present, as well as classifying those objects.
- Some of the most important elements that are now staple in most of state-of-the art algorithms include inception and residual blocks, skip connections and upsampling.
YOLO

- Real-time Object Detection with YOLO, YOLOv2 and now YOLOv3
- Gentle guide on how YOLO Object Localization works with Keras
- How to implement a YOLO (v3) object detector from scratch in PyTorch
YOLOv1
- YOLO ("you only look once") is a popular algoritm because it achieves high accuracy while also being able to run in real-time.
- This algorithm "only looks once" at the image in the sense that it requires only one forward propagation pass through the network to make predictions.
- After non-max suppression, it then outputs recognized objects together with the bounding boxes.
- YOLO uses a single CNN network for both classification and localizing the object using bounding boxes.
- You Only Look Once: Unified, Real-Time Object Detection (2015)
Segmentation
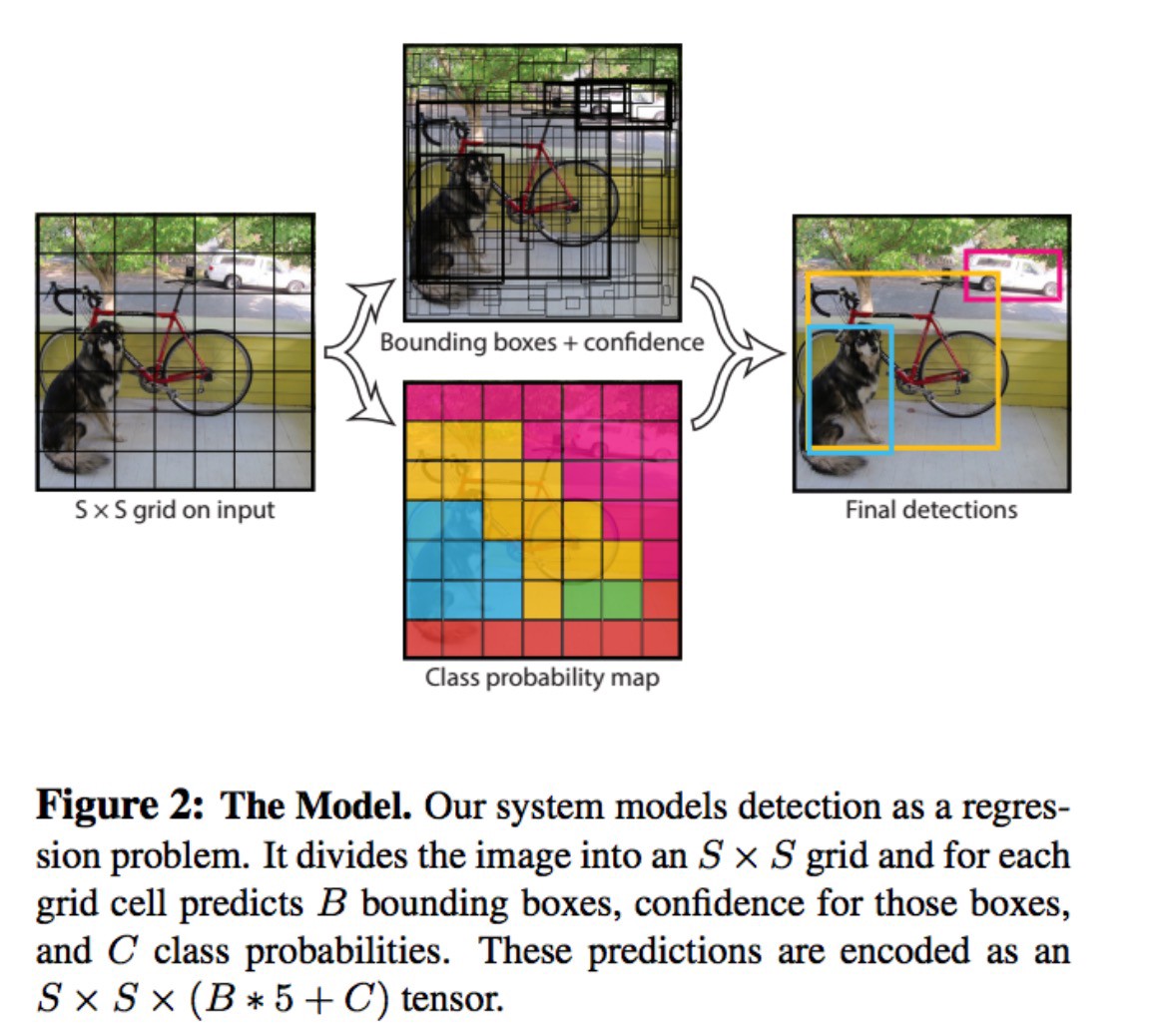
- The input image is divided into an SxS grid of cells.
- For each object that is present on the image, one grid cell is said to be “responsible” for predicting it (that is, the cell where the center of the object falls into)
- The division is done with the convolution sliding window, which is more efficient than classical sliding windows detection algorithm, because it shares the computations for each of the sliding windows.
- Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance.
- The (effective) receptive field of those output neurons is much larger than the cell and actually cover the entire image.
Prediction
- YOLO predicts multiple bounding boxes per grid cell.
- A bounding box describes the rectangle that encloses an object.
- For each grid cell:
- predicts B boundary boxes and each box has one box confidence score,
- detects one object only regardless of the number of boxes B,
- predicts C conditional class probabilities (one per class for the likeliness of the object class).
Bounding boxes
- Each bounding box contains 5 elements: \((x, y, w, h)\) and a box confidence score.
- The \((x, y)\) coordinates represent the center of the box, relative to the grid cell location.
- These coordinates are normalized to fall between zero and one.
- The \((w, h)\) box dimensions are also normalized to \([0, 1]\), relative to the image size.
- The confidence score reflects how likely the box contains an object (objectness) and how accurate is the bounding box.
- If no object exists in that cell, the confidence score should be zero.
Conditional class probabilities
- The conditional class probability is the probability that the detected object belongs to a particular class (one probability per category for each cell)
Evaluation
- The class confidence score for each prediction box measures the confidence on both the classification and the localization.
- If no object exists in that cell, the confidence score should be zero.
- Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth.
$$\text{box confidence score}=P_r(\text{object})\cdot{\text{IoU}}$$ $$\text{conditional class probability}=P_r(\text{class}_i|\text{object})$$ $$\text{class confidence score}=P_r(\text{class}_i)\cdot{\text{IoU}}$$ $$\text{class confidence score}=\text{box confidence score}\times\text{conditional class probability}$$
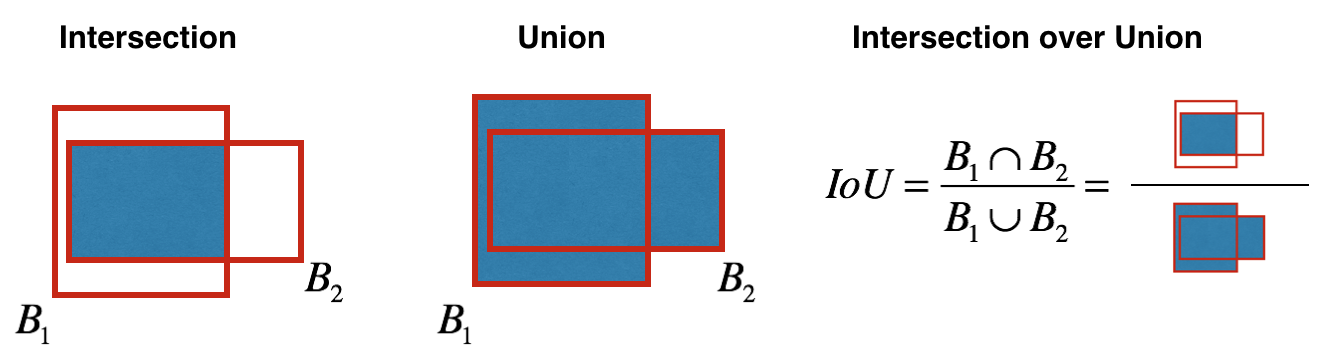
Intersection over union (IOU)
- Intersection over Union, or Jaccard index, is an evaluation metric used to measure the accuracy of an object detector.
- It computes size of intersection and divide it by the union. More generally, IOU is a measure of the overlap between two bounding boxes.
- The higher the IOU the better is the accuracy.
- An IOU score \(\text{IoU}\ge{0.5}\) is normally considered as a true positive.
Non-maximum suppression (NMS)
- NMS eliminates some candidates that are in fact different detections of the same object, without removing the candidates for different objects.

- For each object class:
- discard all those bounding boxes where probability of object being present is below some threshold (0.6),
- take the bounding box with the highest score among candidates,
- discard any remaining bounding boxes with IOU value above some threshold (0.5)
- Non-maximal suppression adds 2-3% in mAP.
Loss function
- YOLO uses sum-squared error between the predictions and the ground truth to calculate loss.
- The loss function is composed of
- the classification loss,
- the localization loss (errors between the predicted boundary box and the ground truth),
- and the confidence loss (the objectness of the box).
- We can put more emphasis on any of the terms by multiplying it with a factor.
Pros
- Fast:
- Good for real-time processing.
- Predictions (object locations and classes) are made from one single network:
- Can be trained end-to-end to improve accuracy.
- YOLO is more generalized:
- Outperforms other methods when generalizing from natural images to other domains like artwork.
- Region proposal methods limit the classifier to the specific region:
- Accesses to the whole image in predicting boundaries. With the additional context, YOLO demonstrates fewer false positives in background areas.
- YOLO detects one object per grid cell:
- Enforces spatial diversity in making predictions.
YOLOv2
- Adds BatchNorm to convolutional layers.
- Uses anchor boxes like Faster-RCNN, the classification is done per-box shape, instead of per each grid-cell.
- Instead of manually choosing the box shape, uses K-means.
- Trains the network at multiple scales (224x224 then 448x448), as the network is now fully convolutional (no FC layer) this is easy to do.
- Combine labels in different datasets to form a tree-like structure WordTree.
- YOLO9000: Better, Faster, Stronger (2016)
Anchor boxes
- After doing some clustering studies on ground truth labels, it turns out that most bounding boxes have certain height-width ratios. So instead of directly predicting a bounding box, YOLOv2 (and v3) predict off-sets from a predetermined set of boxes with particular height-width ratios - those predetermined set of boxes are the anchor boxes.
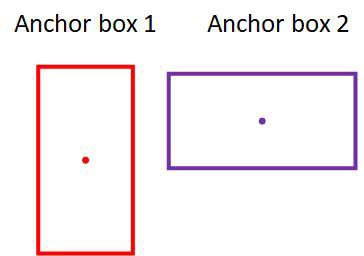
- Anchor box makes it possible to detect multiple objects centered in one grid cell.
- The idea of anchor box adds one more "dimension" to the output labels by pre-defining a number of anchor boxes:
- We move the class prediction from the cell level to the boundary box level.
- Now, each prediction includes 4 parameters for the boundary box, 1 box confidence score (objectness) and class probabilities.
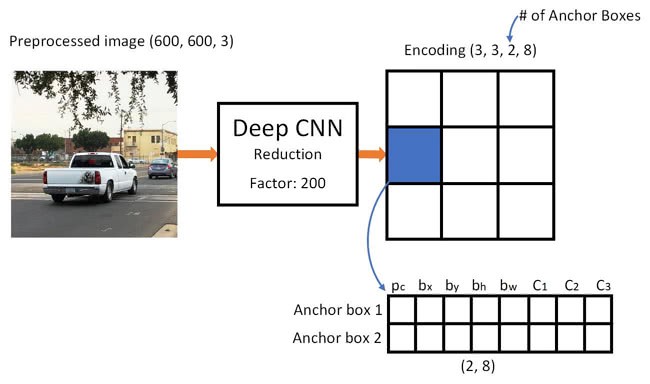
- The anchor boxes need to be predefined either by hand or by using an algorithm such as K-Means (where distance is IOU)
- One reason for choosing a variety of anchor box shapes is the similarity of one object’s bounding box shape to the shape of the anchor box.
- Another reason is to allow the model to specialize better.
- Anchor boxes decrease mAP slightly from 69.5 to 69.2 but the recall improves from 81% to 88%. i.e. even the accuracy is slightly decreased but it increases the chances of detecting all the ground truth objects.
Pros
- Faster
- More Accurate (73.4 mAP on Pascal dataset)
- Can detect up to 9000 classes (20 before)
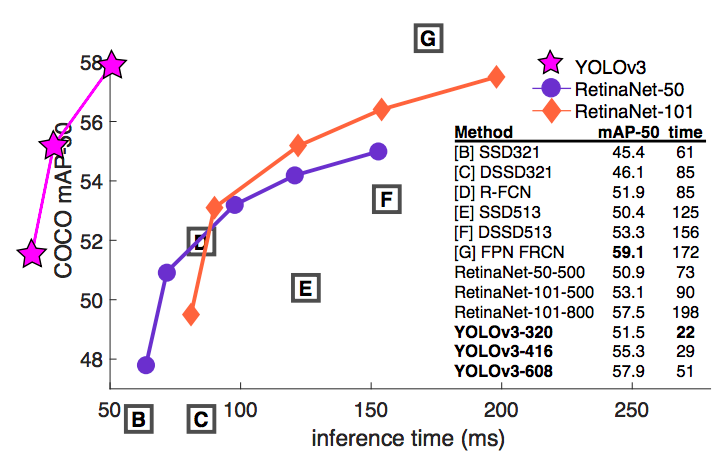
YOLOv3
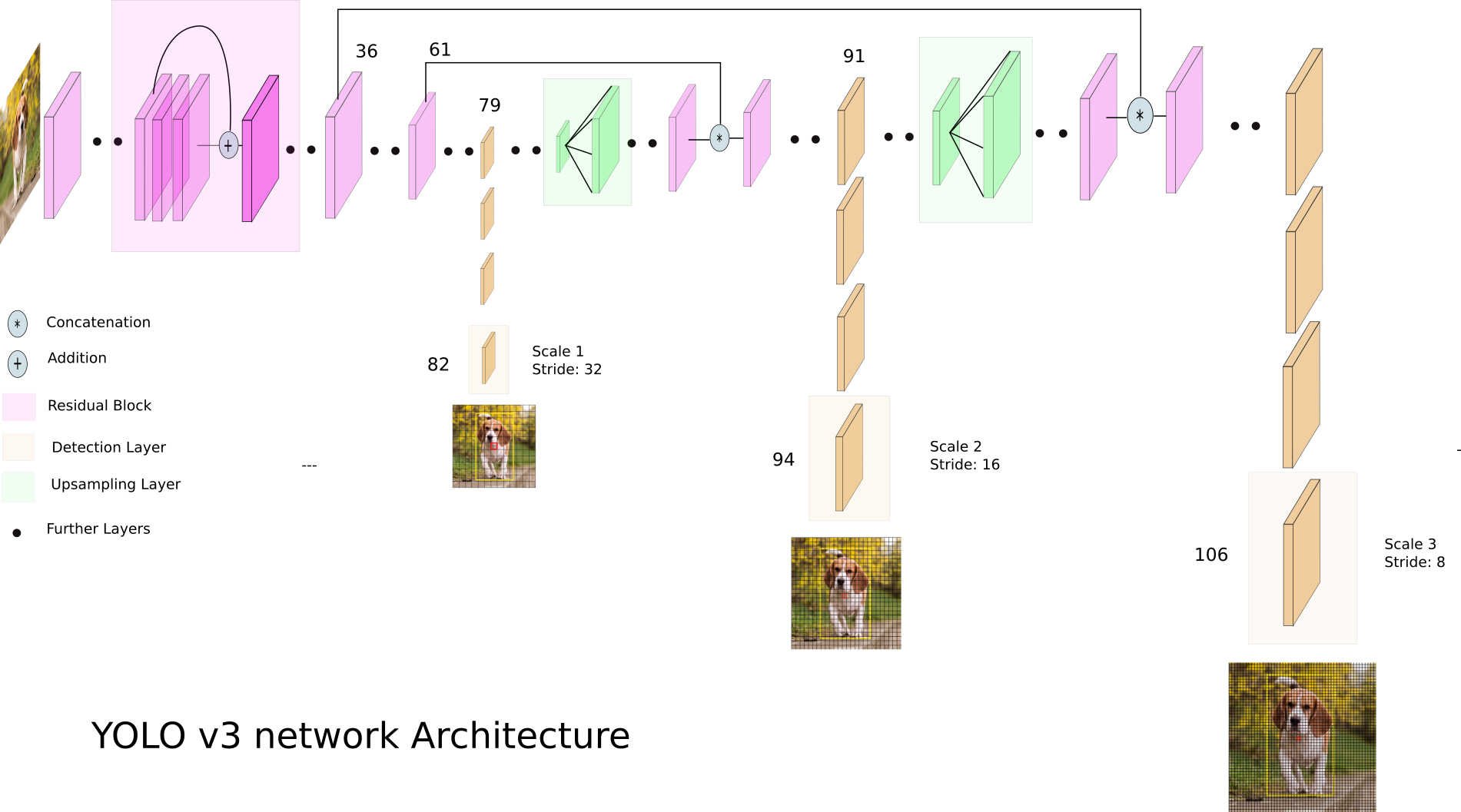
Detection at three scales
- The most salient feature of v3 is that it makes prediction at three scales, which are precisely given by downsampling the dimensions of the input image by 32, 16 and 8 respectively.
- The detection is done by applying 1x1 detection kernels on feature maps of three different sizes at three different places in the network.
Detecting smaller objects
- Detections at different layers helps address the issue of detecting small objects, a frequent complaint with YOLOv2.
- The upsampled layers concatenated with the previous layers help preserve the fine grained features which help in detecting small objects.
More anchor boxes
- YOLOv3, in total uses 9 anchor boxes:
- Three for each scale.
- If you’re training YOLO on your own dataset, you should go about using K-Means clustering to generate 9 anchors.
- YOLOv3 predicts 10x the number of boxes predicted by YOLOv2.
Logistic regression
- Squared errors have been replaced by cross-entropy error terms. In other words, object confidence and class predictions are now predicted through logistic regression.
Multilabel classification
- YOLOv3 now performs multilabel classification for objects detected in images.
- Softmaxing classes rests on the assumption that classes are mutually exclusive, or in simple words, if an object belongs to one class, then it cannot belong to the other. However, when we have classes like Person and Women in a dataset, then the above assumption fails.
Pros
- YOLOv3 performs at par with other state of art detectors like RetinaNet, while being considerably faster.