Data is placed in tables and data schema is carefully designed before the database is built.
Relational database management system (RDBMS) is used to maintain relational databases.
Invented by E. F. Codd in 1970.
Oracle (banking), Teradata, MySQL, PostgreSQL, SQLite (simplex tasks, development)
Structured Query Language (SQL) is the language for querying and maintaining relational databases.
Virtually every RDBMS uses SQL.
SQL is the most common standardized language used to access databases.
The SQL standard has been evolving since 1986.
To operate efficiently and accurately, RDBMS must use ACID transactions.
The programming within a RDBMS is usually accomplished using stored procedures (SPs)
Those are sets of SQL statements which are stored as a group, reused and shared.
Relational databases typically provide indexing.
The use of efficient indexes can dramatically improve query performance
Indices are usually implemented via B+ trees, R-trees, and bitmaps.
Use cases:
You need ACID compliancy.
Your data is structured and unchanging.
Large-scale web organizations such as Google and Amazon employ relational databases as adjuncts where high-grade data consistency is necessary.
SQL Vs NoSQL: The Differences Explained
Atomicity: The whole transaction is processed or nothing is processed.
For example, debit and credit operations cannot occur partially.
Consistency: Any data written to the database must be valid according to all defined rules.
For example, a column of type integer does not accept boolean values.
Isolation: Transactions are processed independently and securely, order does not matter.
But complete isolation uses more system resources and transactions blocking each other.
Durability: Committed transactions remain committed even in case of system failure.
For example, a flight seat remains booked even after a crash.
Small to medium sized data volumes.
Complex query intensive environment:
Support for JOINS, aggregations and analytics.
Support for secondary indexes to help with quick searching.
ACID transactions guarantee accuracy, completeness, and data integrity.
Stable enough in high load and for complex transactional applications.
Remember, financial systems are built on trust.
Easier to change to business requirements:
Modeling the data, not modeling queries.
Have better support, product suites and add-ons to manage these databases.
No need to do queries first, run them based on the schemas and ERD.
Not suited for large amounts of data as they cannot scale horizontally.
Not highly available because of a single point of failure.
Not designed to handle unstructured and hierarchical data.
The atomicity of the operations plays a crucial part in the database’s performance.
ACID transactions slow down the process of reading and writing data.
Have a predefined (not flexible) schema.
Denormalization: Add redundant copies of data or by grouping data to get faster reads.
Caching layers (memcached): Distributed memory cache sitting on top of the database.
Sharding: Split up the database into range partitions.
Materialized views: Materialize views to serve the services in the format they expect and faster.
Removing stored procedures: Remove expensive logic.
The relational data model allows to create a consistent, logical representation of information.
The data is stored in relations (tables)
Each relation consists of tuples (rows, records) and attributes (columns, fields).
Tables that are not stored but computed on the fly are called views or queries.
Consistency is achieved by including declared constraints (logical schema)
Constraints provide one method of implementing business rules in the database.
Constraints can apply to attributes, tuples or to an entire relation.
There are key, domain, and referential integrity constraints.
A domain describes the set of possible values for a given attribute.
Relationships are a logical connection between different tables.
Defines how the data are to be manipulated (relational calculus)
SUPERKEY is a set of attributes whose values can be used to uniquely identify a tuple.
CANDIDATE KEY is a minimal set of attributes necessary to identify a tuple.
Also called a MINIMAL SUPERKEY.
Usually one CANDIDATE KEY is chosen to be called the PRIMARY KEY.
Other CANDIDATE KEYS are called ALTERNATE KEYS.
PRIMARY KEY ensures that the column(s) has no NULL values, and that every value is unique.
Must be unique for each record.
Must apply uniform rules for all records.
Must stand the test of time.
Must be read-only (to avoid typos and varying formats).
Physically, implemented as a unique index.
SURROGATE KEY is a key which is not natural.
A natural key is a key that has contextual or business meaning (STORE, SALES).
For example, an increasing sequential integer or “counter” value.
Can be extremely useful for analytical purposes.
FOREIGN KEY is a column in one table that refers to the PRIMARY KEY in other table.
Normalization means organizing tables in a manner that reduces redundancy and dependency of data.
Redundant data wastes disk space and creates maintenance problems.
If data exists in more than one place, it must be changed in all locations.
The process is progressive (a higher level cannot be achieved before the previous levels)
Divides larger tables to smaller tables and links them using relationships.
The end result should feel natural.
Objectives of normalization:
Free the database from unwanted insertions, updates & deletion dependencies.
Reduce the need for refactoring the database as new types of data are introduced.
Make the relational model more informative to users.
Make the database neutral to the query statistics (do not model queries beforehand!)
Credit
First Normal Form (1NF) :
Make the columns atomic: cells have a single value.
Define the primary key: no repeating groups in individual tables.
Columns must contain values of the same type.
The order in which data is stored does not matter.
May still contain partial and/or transitive dependencies.
Second Normal Form (2NF) :
Have reached 1NF
Split up all data resulting in many-to-many relationships.
Create relationships between tables by use of foreign keys.
Is the identifier comprised of more than one attribute?
If so, are any attribute values dependent on just part of the key?
Remove partial dependencies: every non-key attribute must depend on the whole key.
May still contain transitive dependencies.
Third Normal Form (3NF) :
Have reached 2NF
Do any attribute values depend on an attribute that is not the key?
Remove transitive dependencies: non-prime attributes are independent of one another.
However, many small tables may degrade performance.
Boyce-Codd Normal Form (BCNF) :
Have reached 3NF
Remove non-trivial functional dependencies.
Happens if there are two or more overlapping composite candidate keys.
Sometimes referred to as 3.5NF
In most practical applications, normalization achieves its best in 3NF.
Normal forms - Wikipedia
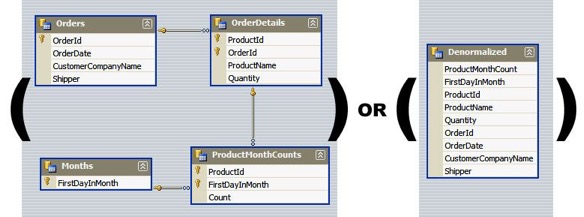
JOINS on the database allow for outstanding flexibility but are extremely slow.
Adding redundant data improves read performance at the expense of write performance.
Credit
Requires more space on the system since there are more copies of the data.
Not really a limiting factor as storage has become less expensive.
Denormalized data model is not the same as a data model that has not been normalized:
Denormalization should only take place after normalization.
With denormalization we want to think about the queries beforehand.
MySQL is the most popular Open Source RDBMS.
The logical model includes objects such as databases, tables, views, rows, and columns.
The database structures are organized into physical files optimized for speed.
It is developed, distributed, and supported by Oracle.
MySQL is Open Source and part of LAMP (Linux, Apache, MySQL, PHP/Perl/Python) environment.
It has a huge community, extensive testing and quite a bit of stability.
In contrast to PostgreSQL, commercial distribution requires a paid license though.
Given that the server hardware is optimal, MySQL runs very fast.
MySQL is faster, more reliable and cheaper because of its unique storage engine architecture.
Understands standards based SQL (Structured Query Language).
Follows a client/server architecture consisting of a database server and arbitrarily many clients.
MySQL Server is a multithreaded SQL server.
Designed to be fully multithreaded using kernel threads, to easily use multiple CPUs.
Supports sharding and can be replicated across multiple nodes for more scalability and availability.
Supports a large number of platforms, client programs and libraries, administrative tools and APIs.
Supports JDBC and JDBC
Provides transactional and non-transactional storage engines.
Designed to make it relatively easy to add other storage engines.
Other features:
Roll-backs, commit and crash recovery
Triggers, stored procedures and views
The Main Features of MySQL
An object-relational database (ORD) is composed of both RDBMS and OODBMS.
Supports sets and lists, arbitrary user-defined datatypes as well as nested objects.
Allows developers to build and innovate their own data types and methods.
Supports object-oriented database model: objects, classes and inheritance.
Very similar to objects used in object-oriented programming.
Supports relationships between objects to easily collect related records.
CREATE TABLE Customers (
Id Cust_Id NOT NULL PRIMARY KEY ,
Name PersonName NOT NULL ,
DOB DATE NOT NULL
);
SELECT Formal(C.Id)
FROM Customers C
WHERE BirthDay(C.DOB) = TODAY;
One of the most popular and advanced solutions is PostgreSQL.
PostgreSQL is an enterprise-class open source ORDBMS.
Not owned by any organization.
Some most prominent features:
Supports both SQL for relational and JSON for non-relational queries.
Backed by an experienced community of developers who have made tremendous contribution.
Supports advanced data types and advance performance optimization.
The first database to implement multi-version concurrency control (MVCC)
Compliant with the ANSI SQL standard (160/179 functions as of 2018)
Completely ACID compliant (in contrast to MySQL)
Highly extensible with custom data types, functions, and even code.
Supports synchronous and asynchronous replication for high availability.
More suited for complex queries, data warehousing and fast read-write speeds.
Why use PostgreSQL? Performance Tuning Queries in PostgreSQL SQLite vs MySQL vs PostgreSQL: A Comparison Of Relational Database Management Systems
A columnar DBMS stores data tables by column rather than by row.
Stores each column in one or more contiguous blocks.
Basically a row-store with an index on every column.
Most column oriented databases are relational.
Some relational databases can use columnar storage, such as PostgreSQL with cstore_fdw.
Optimized for fast retrieval of columns of data, typically in OLAP applications.
Pros:
High-speed searching, scanning, and aggregation capabilities.
Ability to scale out easily.
Drastically reduce the overall disk I/O operations.
Most columnar databases compress similar data to reduce storage.
Cons:
Operations that retrieve the entire row are slower (but rare)
INSERTs must be separated into columns and compressed as they are stored.
OLTP constraints can be mediated using in-memory data storage.
10:001,12:002,11:003,22:004;
Smith:001,Jones:002,Johnson:003,Jones:004;
goodreads.com:001,google.com:002,gamerassaultweekly.com:003