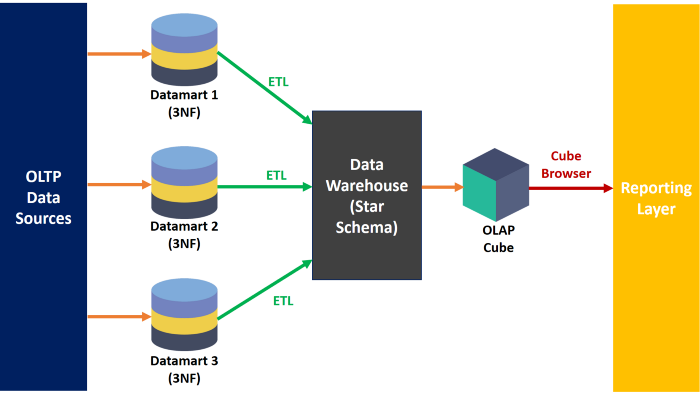
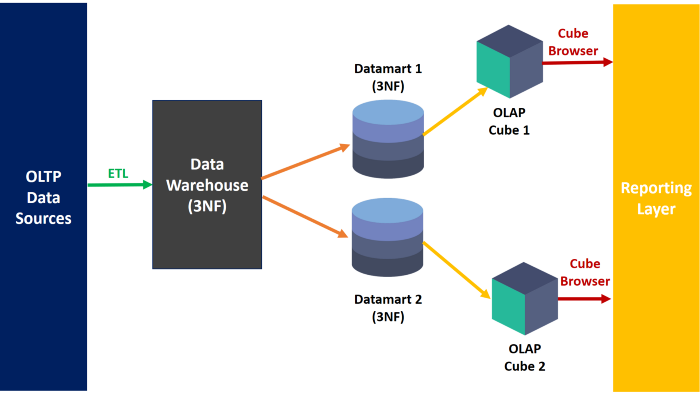
A data warehouse (DWH) is a centralized database system that retrieves and consolidates data from multiple applications and sources into one location for BI and other analytical activities.
Subject-oriented, integrated, non-volatile, and time-variant
Use case: Queries that need to incorporate data from multiple data sources across the organization.
SQL databases are not sufficient on their own:
Retailer has a nation-wide presence → Scale?
Acquired smaller retailers, brick & mortar shops, online store → Single database? Complexity?
Has support call center & social media accounts → Tabular data?
Customers, Inventory Staff and Delivery staff expect the system to be fast & stable → Performance
HR, Marketing & Sales Reports want a lot information but have not decided yet on everything they need → Clear Requirements?
Data is available:
In an understandable & performant dimensional model.
With conformed dimensions or separate data marts.
For users to report and visualize by interacting directly with the model or, in most cases, through a BI application.
Slow analytical queries and a schema that is hard to understand.
Might be OK for small datasets.
ETL process
ETL is a type of data integration that refers to the three steps (extract, transform, load) used to blend data from multiple sources and (often) to build a data warehouse.
A core component of an organization’s data integration toolbox.
Extraction:
The data is extracted from multiple and different types of sources into the staging area.
Common types of sources include relational databases, XML, JSON and flat files.
Staging area allows for data validation (unwanted/duplicated data, data type check)
Extraction should not affect performance of the source systems.
Transformation:
The data is cleansed, mapped and transformed into a proper format.
Occurs by using rules or lookup tables or by combining the data with other data.
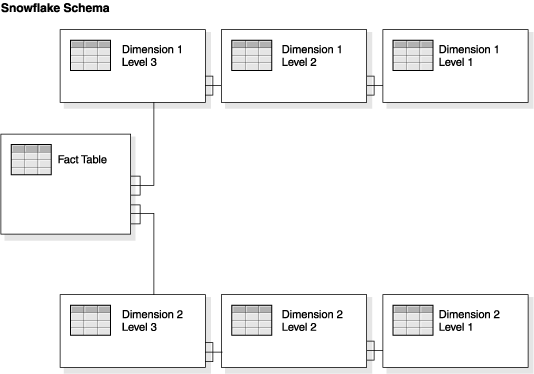
The DWH is built using the Inmon model and on top of the integrated data warehouse, the business process oriented data marts are built using the star schema for reporting.
Dimensional modeling
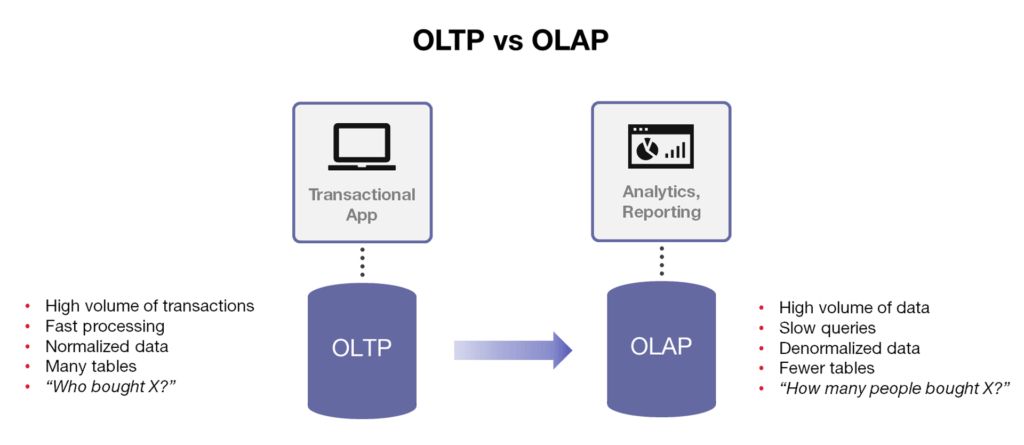
Dimensional modeling is primarily used to support OLAP and decision making while ER modeling is best fit for OLTP where results consist of detailed information of entities rather an aggregated view.
Pros of dimensional modeling:
Easier to understand and more intuitive to a business user.
More denormalized and optimized for data querying.
Scalable and easily accommodate unexpected new data.
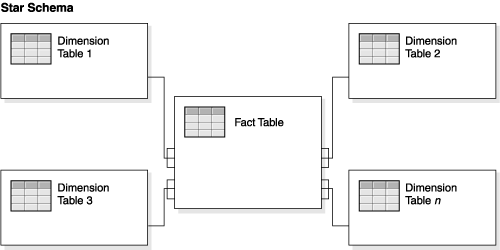
Uses the concepts of facts (measures) and dimensions (context).
Fact tables record business events.
For example: Store sales
Each row (= event) contains the measurement data (facts) associated with that event.
Facts are typically numeric columns that can be aggregated.
They can be additive (sales per unit), non additive, and semi additive.
Grain of the table is the level of detail (daily or monthly sales?)
Two types of columns: facts and foreign keys to dimension tables.
The primary key is usually a composite key that is made up of foreign keys.
Dimension tables describe the events in fact tables.
For example: People, products, place and time
Usually have a relatively small number of records compared to fact tables.
But each record may have a very large number of columns.
Dimensions are typically discrete columns for filtering.
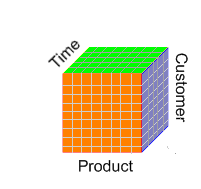
Rotate the whole cube, giving another perspective on the data.
For example, replace products with time periods to see data across time for a single product.
SELECT'TotalSalary'AS TotalSalaryByDept, [30], [45]
FROM (SELECT dept_id, salary FROM employees) AS SourceTable
PIVOT (SUM(salary) FOR dept_id IN ([30], [45])) AS PivotTable;
Types
MOLAP
Pre-aggregate the OLAP cubes and save them on a special purpose non-relational database.
Pros:
Fast query performance due to indexing and storage optimizations.
Smaller on-disk size due to compression.
Very compact for low dimension datasets.
Cons:
The processing step can be quite lengthy, especially on large data volumes.
Database explosion if high number of dimensions or sparse multidimensional data.
ROLAP
Compute the OLAP cubes on the fly from the existing relational databases.
The source database must still be carefully designed for ROLAP use (e.g. columnar storage)
Pros:
Have the ability to ask any question.
More scalable in handling large data volumes and many dimensions.
Load times are generally much shorter than for MOLAP.
The data can be accessed by any SQL reporting tool.
Cons:
Slower query performance as opposed to MOLAP.
The load task must be managed by custom ETL code.
Relies on the source databases for querying and caching.
HOLAP
Divide data between relational and specialized storage.
Benefits from greater scalability of ROLAP and faster computation of MOLAP.
Amazon Redshift
Amazon Redshift is a fully managed, column-oriented, petabyte-scale data warehouse in the cloud.
Can build a central data warehouse unifying data from many sources.
Can run big, complex analytic queries against that data with SQL.
Can report and pass on the results to dashboards or other apps.
Behind the scenes, Redshift stores relational data in column format.
Based on industry-standard PostgreSQL.
Supports high compression and in-memory operations.
Columnar storage reduces the number of disk I/O requests and the amount of data.
Integrates with various data loading and ETL tools and BI reporting, data mining, and analytics tools.
Also provides its own Query Editor.
Accessible, like any relational database, via JDBC/ODBC.
Designed to crunch data, i.e. running “big” or “heavy” queries against large datasets.
Can ingest huge structured, semi-structured and unstructured datasets (via S3 or DynamoDB)
It's a database, so it can store raw data AND the results of transformations.
Can run analytic queries against data stored Amazon S3 data lake.
Redshift Spectrum: Run queries against data in Amazon S3 without moving it.
Can query open file formats, such as CSV, JSON, Parquet, and more.
Dense Compute (DC): fast CPUs, large amounts of RAM, and solid-state disks (SSDs).
Dense Storage (DS): cost-effective, lots of storage, a very low price point.
Can scale out easily by changing the number or type of nodes.
Redshift is a fully managed service on AWS.
Redshift automatically provisions the infrastructure with just a few clicks.
Most administrative tasks are automated, such as backups and replication.
Ensures fault tolerance of the cluster.
Can use SSL to secure data in transit and run within Amazon VPC.
Has a price-point that is unheard of in the world of data warehousing ($935/TB annually)
Offers On-Demand pricing with no up-front costs.
Compared to Amazon RDS
RDS is Amazon's relational databases as a service offering.
Supports engines such as Amazon Aurora, Oracle, PostgreSQL, MySQL, and many others.
RDS meant to be used as the main or a supporting data store and transactional (OLTP) database.
Both services can be used together very effectively: RDS as a source, Redshift as a target.
Amazon RDS is primarily used by end customers, while Redshift by internal users (data scientists)
Architecture
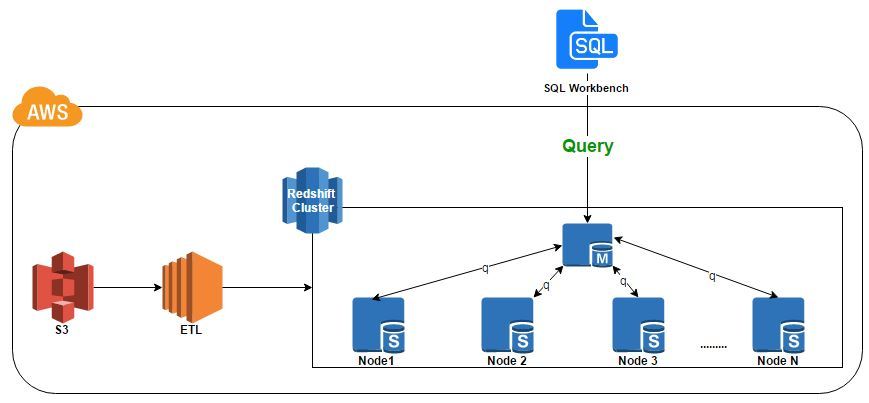
The core component is a cluster, which is composed of one or more compute nodes.
Leader node coordinates the compute nodes and handles external communication.
Client interacts only with the leader node, but compute nodes remain transparent.
Develops execution plans to carry out database operations.
Optimizes query execution.
Distributes SQL statements to the compute nodes (only if they have relevant partition)
Compute nodes (EC2 instances) execute the compiled code and send intermediate results back.
Each compute node has its own dedicated CPU, memory, and disk storage.
One can increase the number of nodes (scale out) or upgrade the node type (scale up)
Each compute node is logically partitioned into slices:
Each slice is allocated 1 CPU, a portion of the node's memory and disk space.
A cluster with \(N\) slices can process \(N\) partitions simultaneously.
For example, 4 compute nodes x 8 slices = maximum 32 partitions.
One can optionally specify one column as the distribution key.
Data modeling
A COPY command is the most efficient way to load a table.
Leverages MPP to read from multiple data files or streams simultaneously.
On contrary, the INSERT command inserts record by record and can be slow.
For better load performance, split data into multiple files:
The number of files should be a multiple of the number of slices in the cluster.
The files should be roughly the same size (1MB-1GB)
Specify a common prefix or a manifest file.
// Example: venue.txt split into files
venue.txt.1
venue.txt.2
venue.txt.3
venue.txt.4
By default, Redshift (blindly) distributes the workload uniformly among the nodes in the cluster.
For better execution performance, set distribution keys on tables:
To minimize data movement during query execution.
To ensure that every row is collocated for every join that the table participates in.
Distribution styles:
EVEN: Appropriate for load balancing and when a table does not participate in joins.
ALL: A copy of the entire table is distributed to every node (broadcasting). For small tables.
KEY: The rows are distributed according to the values in one column. The leader node collocates the rows on the slices according to the values in the joining columns so that matching values from the common columns are physically stored together. For large tables.
AUTO: Automatic assignment based on the size of the table data.
Sorting enables efficient handling of range-restricted predicates.
Define one or more of its columns as sort keys.
Allows exploitation of the way that the data is sorted.
Useful for columns that are frequently used in ORDER BY like dates.
-- Example: 2x speed improvement using distribution and sort keyscreatetable activity (
idinteger primary key,
created_at date sortkey distkey,
device varchar(30)
);
Defining constraints:
Uniqueness, primary key, and foreign key constraints are not enforced.
But declare constraints anyway when you know that they are valid.
Redshift enforces NOT NULL column constraints.
One can apply a compression type, or encoding, to the columns in a table.
Reduces the amount of disk I/O and therefore improves query performance.
Use the COPY command to apply compression automatically.