CNN Architectures
- According to the universal approximation theorem, given enough capacity, we know that a feedforward network with a single layer is sufficient to represent any function. However, the layer might be massive and the network is prone to overfitting the data. Therefore, there is a common trend in the research community that our network architecture needs to go deeper.

- The less data you have, the more hand-engineering ("hacks") you need. The more data you have, the simpler the learning algorithm becomes (think of end-to-end learning).
- We are developing complex network architectures to compensate for the lack of labeled data.
- LeNet-5: Gradient-Based Learning Applied to Document Recognition (1998)
- AlexNet: ImageNet Classification with Deep Convolutional Neural Networks (2012)
- VGG-16: Very Deep Convolutional Networks for Large-Scale Image Recognition (2015)
- Bag of Tricks for Image Classification with Convolutional Neural Networks (2018)
Inception (GoogLeNet)
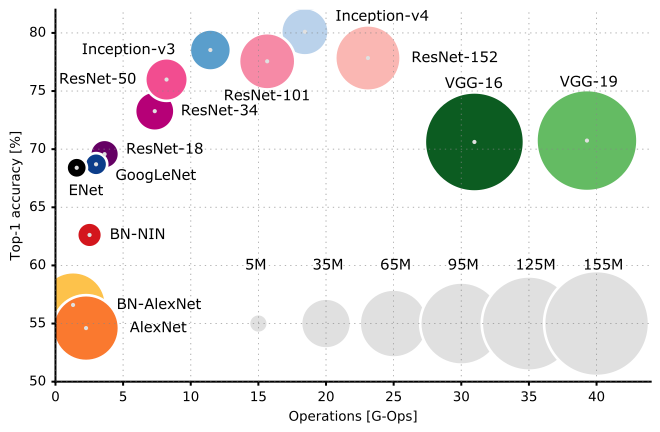
- While earlier networks achieve a phenomenal accuracy on ImageNet dataset, their deployment on even the most modest sized GPUs is a problem because of huge computational requirements, both in terms of memory and time.
- The GoogLeNet builds on the idea that most of the activations in a deep network are either unnecessary (value of zero) or redundant because of correlations between them.
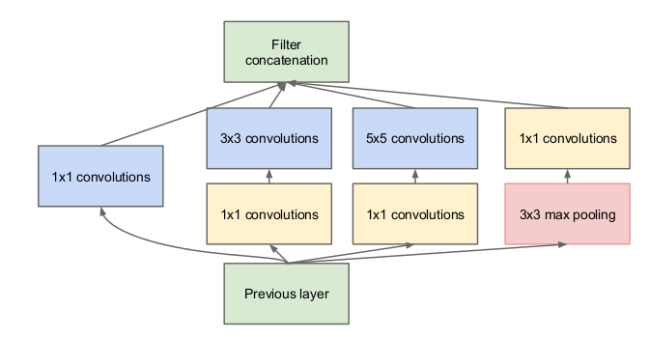
- So GoogLeNet created a module called "inception module" that approximates a sparse CNN with a normal dense construction. Since only a small number of neurons are effective, the number of the convolutional filters of a particular kernel size is kept small. Also, it uses convolutions of different sizes to capture details at varied scales (5x5, 3x3, 1x1).
- The inception network is formed by placing a large number of inception blocks to form a “deep” inception network.
- Inception v1 (2014)
- Inception v2 and Inception v3 (2015)
- Inception v4 and Inception-ResNet (2016)
- A Simple Guide to the Versions of the Inception Network
Advances
Bottleneck (1x1 convolution)
- Large convolution operations are computationally expensive.
- To make them cheaper (sometimes 10x), limit the number of input channels by adding an extra 1x1 convolution before larger (3x3, 5x5) convolution operations and after pooling operations.
- It's equivalent to a cross-channel parametric pooling layer.
- In most of applications each convolution is directly succeeded by a non-linear activation.
![]()
Variation in object size
- Salient parts in the image can have extremely large variation in size:
- The area occupied by an object is different in each image.
- Choosing the right kernel size for the convolution operation becomes tough.
- Why not have filters with multiple sizes operate on the same level?
- The network essentially would get a bit “wider” rather than “deeper”.
Representational bottleneck
- Reducing the dimensions too much may cause loss of information, known as a “representational bottleneck”.
- Once the information is gone, it can't be reconstructed.
- For this, the filter banks in the module are expanded
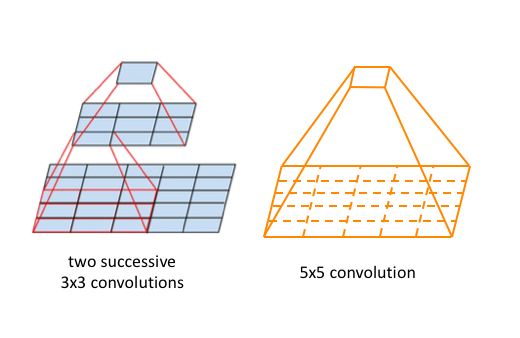
Factorization methods
- Convolutions can be made more efficient in terms of computational complexity:
- Factorize convolutions of filter size nxn to a combination of 1xn and nx1 convolutions.
Auxiliary classifiers
- Inception network is a pretty deep classifier:
- As with any very deep network, it is subject to the vanishing gradient problem.
- To prevent the middle part of the network from “dying out”, the authors of the paper introduced two auxiliary classifiers. They essentially applied softmax to the outputs of two of the inception modules, and computed an auxiliary loss over the same labels.
- It was later discovered that the earliest auxiliary output had no discernible effect on the final quality of the network. The addition of auxiliary outputs primarily benefited the end performance of the model, converging at a slightly better value than the same network architecture without an auxiliary branch. It is believed the addition of auxiliary outputs had a regularizing effect on the network.
Global average pooling (GAP)
- Inception uses a global average pooling followed by the classification layer.
- It allows you to have the input image be any size, not just a fixed size like 227x227.
- GAP takes the average of each feature map and produces a volume of shape 1x1xchannels (e.g., 8x8x10 to 1x1x10).
- GAP is more meaningful and interpretable than FC layers as it enforces correspondance between feature maps and categories.
- Another advantage is that there is no parameter to optimize in the GAP thus overfitting is avoided at this layer.
- Futhermore, global average pooling sums out the spatial information, thus it is more robust to spatial translations of the input.
- Network In Network
ResNet
- Deep Residual Learning for Image Recognition (2015)
- Identity mappings in Deep Residual Networks (2016)
- Aggregated Residual Transformation for Deep Neural Networks (2017)
- An Overview of ResNet and its Variants
Vanishing gradient problem
- The problem with increased depth is that the signal required to change the weights, which arises during backpropagation, becomes very small at the earlier layers. It essentially means that earlier layers are almost negligible learned. This is called vanishing gradient.
- The second problem with training the deeper networks is, performing the optimization on huge parameter space and therefore naively adding the layers leading to higher training error. This is called degradation problem.
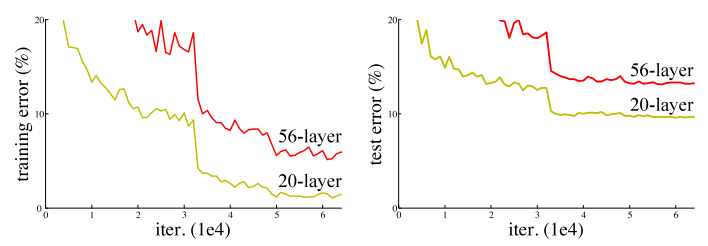
- It is hard to know the desired depth of a deep network:
- If layers are too deep, errors are hard to propagate back correctly.
- If layers are too narrow, we may not learn enough representation power.
Advances
Residual learning
- When He et al. started analyzing Deep Convolutional Networks, they found that their error was greater than shallower networks despite the added layers being identity functions. That is weird, since if all layers added are identity layers, the network should perform at least as well as the base network. This issue was different from the vanishing gradients problems which has been effectively tackled using batch normalization.
- Using this weird behavior as a guiding cue, the authors decided to train a network to learn the feature mapping by learning the residual and adding the original feature vector. This way, even if the residual was 0, the network would just learn the identity mapping. The big idea was that if you took a successful network like AlexNet, VGG, or GoogleNet and added umpteen more layers to it, the network is now allowed to learn a basic identity mapping at later layers so that it can perform at least as well as those networks.
- The residual is given by \(H(x)=F(x)-x\) where \(x\) is the output of the previous layer and \(F(x)\) is the mapping you would normally have the network learn on this layer.
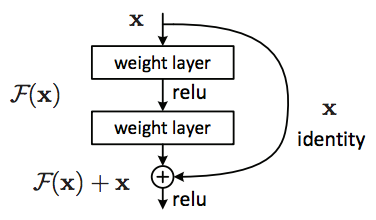
- With identity mapping, the signal can be directly propagated from one layer to another, in both forward and backward direction.
- Residual learning means each subsequent layer in a deep neural network is only responsible for fine tuning the output from the previous layer by adding a learned "residual" to the input. This differs from a more traditional approach where each layer generates the whole output.
- Stacking layers shouldn’t degrade the network performance, because we could simply stack identity mappings (layer that doesn’t do anything) upon the current network, and the resulting architecture would perform the same.
- This way, the network decides how deep it needs to be.
Ensemble-like behavior
- Deep Resnets can be interpreted as large ensembles of much shallower networks.
- ResNet preserves information across layers, similar to ReLU.
- To ensure a minimum loss of information from any of the lower layers, we add passthrough routing so that layers receive more detailed information rather than just abstract information.
- In contrast to VGG, deleting layers causes only gradual degradation of performance.
Biology
- A residual neural network is an artificial neural network (ANN) of a kind that builds on constructs known from pyramidal cells in the cerebral cortex.
Research findings
- Residual nets being equivalent to RNN.
- Residual nets acting more like ensembles across several layers.
- The network’s expressability in the terms of the number of paths, rather than depth, plays a key role in residual networks.
- Networks with residual units deeper in the architecture caused the network to “die” if the number of filters exceeded 1000. Hence, to increase stability, the residual activations are scaled.